Recuperador de URL
O Recuperador de URL permite buscar e processar conteúdo de links da web, com suporte a OCR, extração de metadados e saída flexível para potencializar fluxos de trabalho de IA.
Descrição do componente
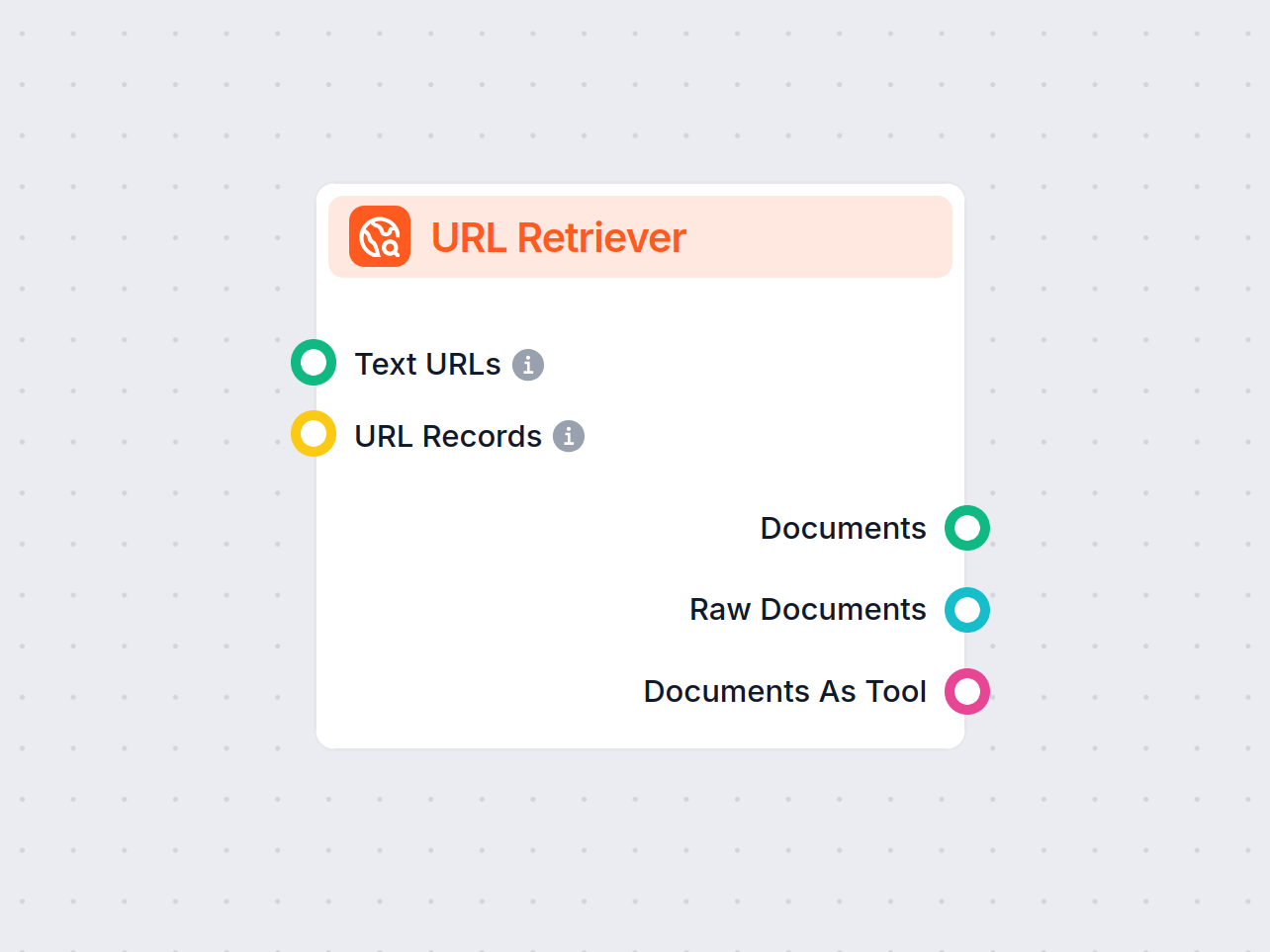
Como o componente Recuperador de URL funciona
Componente Recuperador de URL
O Recuperador de URL é um componente de fluxo versátil projetado para buscar e processar conteúdo da web a partir de URLs especificadas, retornando as informações como documentos estruturados. Ele serve como uma ponte entre o conteúdo online externo e seu fluxo de trabalho de IA, permitindo que você integre, analise ou processe informações baseadas na web de forma eficiente.
O Que Ele Faz?
Este componente recupera o conteúdo de uma ou várias URLs fornecidas como entrada. Ele pode extrair o texto principal, metadados e até processar conteúdo de imagens usando Reconhecimento Óptico de Caracteres (OCR). Os dados recuperados são disponibilizados em vários formatos estruturados adequados para tarefas de IA subsequentes, como sumarização, resposta a perguntas ou extração de conhecimento.
Opções de Entrada
Você pode fornecer URLs ao componente de duas formas:
URLs em Texto:
- Tipo de Entrada:
Message - Descrição: Uma lista de links de URL simples para o componente buscar o conteúdo.
- Tipo de Entrada:
Registros de URL:
- Tipo de Entrada:
UrlRecord - Descrição: Uma lista de registros de URL estruturados, que podem incluir metadados adicionais.
- Tipo de Entrada:
Parâmetros Avançados de Entrada
| Parâmetro | Tipo | Padrão | Descrição |
|---|---|---|---|
| Aplicar OCR | Booleano | false | Se ativado, aplica OCR para extrair texto de imagens no documento. |
| Cache TTL | Dropdown | 2 semanas | Por quanto tempo o conteúdo deve ser armazenado em cache, com opções de sem cache até 1 ano. |
| A partir do H1 se existir | Booleano | true | Inicia a extração a partir da tag H1, se presente, focando no conteúdo principal. |
| Carregar do ponteiro | Booleano | true | Carrega o conteúdo a partir da seção mais relevante com base na sua consulta. |
| Ocultar Recursos | Booleano | false | Oculta os recursos recuperados de serem exibidos ou exportados. |
| Máx. de Tokens | Inteiro | 3000 | Define o número máximo de tokens para o texto de saída. |
| Pular Último Título | Booleano | true | Pula o último título durante a extração para um conteúdo mais enxuto. |
| Estratégia | Dropdown | Incluir tamanho igual de cada documento | Determina como o conteúdo é combinado: concatenar totalmente ou incluir partes iguais de cada documento. |
| Exportar Conteúdo | Multi-select | Todos | Escolha quais elementos HTML exportar (H1-H6, Parágrafo). |
| Incluir Metadados | Multi-select | Produto | Especifique quais campos de metadados incluir (ex.: Produto, Autor, Website, etc.). |
| Verboso | Booleano | false | Ativa saída detalhada para depuração ou informação. |
| Nome da Ferramenta | String | (vazio) | Opcionalmente atribua um nome personalizado à ferramenta para referência do agente. |
| Descrição da Ferramenta | Multilinha | (vazio) | Forneça uma descrição para ajudar agentes a entender o propósito da ferramenta. |
Saídas
O Recuperador de URL fornece suas saídas em vários formatos, permitindo integração flexível com diferentes processos de IA:
| Nome da Saída | Tipo | Descrição |
|---|---|---|
| Documentos | Mensagem | O conteúdo processado das URLs, pronto para uso em fluxos de trabalho orientados a mensagens. |
| Documentos Brutos | Documento | Os objetos de documento brutos, não processados, para processamento avançado posterior. |
| Documentos como Ferramenta | Ferramenta | O conteúdo empacotado como ferramenta, permitindo que fluxos baseados em agentes utilizem os documentos. |
Por Que Usar o Recuperador de URL?
- Integre Conhecimento Externo: Traga informações da web facilmente para suas aplicações de IA, como chatbots, motores de busca ou bases de conhecimento.
- Extração Personalizável: Ajuste exatamente o conteúdo e metadados desejados, controle a quantidade de dados e utilize OCR para imagens.
- Desempenho & Eficiência: Use cache para evitar downloads redundantes e limite a saída de tokens para performance.
- Formatos de Saída Flexíveis: Escolha o formato de saída que melhor se encaixa no próximo passo do seu fluxo—documento estruturado, mensagem ou ferramenta.
Exemplos de Uso
- Construção de agentes conversacionais baseados em conhecimento que respondem perguntas com conteúdo da web atualizado.
- Agregação de dados de produtos de sites de e-commerce para comparação ou análise.
- Monitoramento e análise de artigos de blog ou notícias com base em tópicos ou palavras-chave específicas.
- Extração de informações de páginas da web contendo mídia mista (texto e imagens).
Tabela Resumo
| Recurso | Descrição |
|---|---|
| Busca URLs | Recupera e processa conteúdo da web a partir das URLs fornecidas. |
| Suporte a OCR | Extrai texto de imagens em documentos, se ativado. |
| Extração de Metadados | Inclui opcionalmente metadados como autor, produto ou tipos schema.org. |
| Saída Personalizável | Selecione quais elementos HTML ou metadados exportar. |
| Cache | Tempos de cache configuráveis para eficiência. |
| Vários Tipos de Saída | Suporta saída em mensagem, documento bruto e ferramenta para flexibilidade. |
O Recuperador de URL é uma ponte poderosa e flexível entre conteúdo da web e seus fluxos de trabalho de IA, oferecendo controle granular sobre a extração e integração de conteúdo.
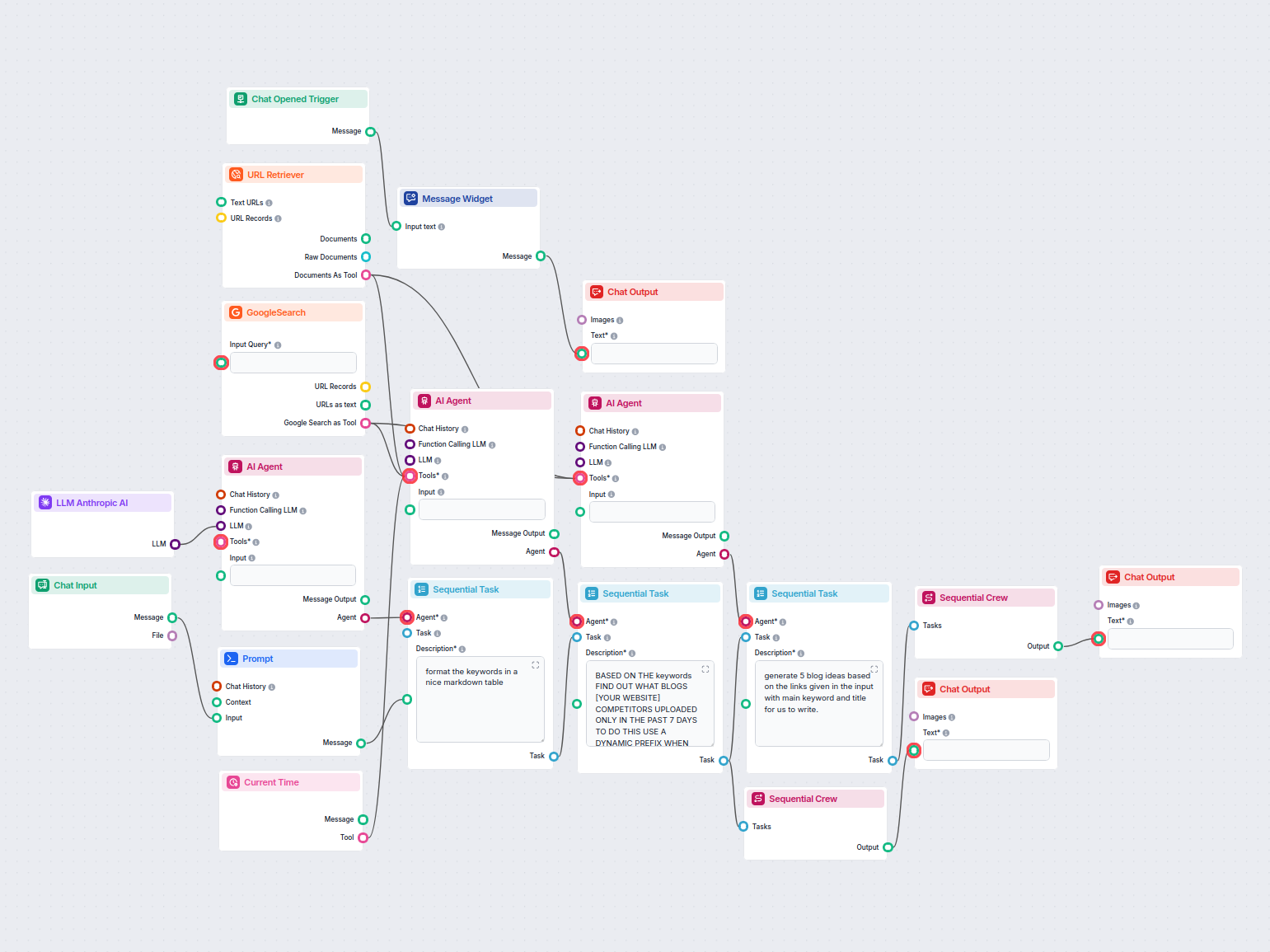
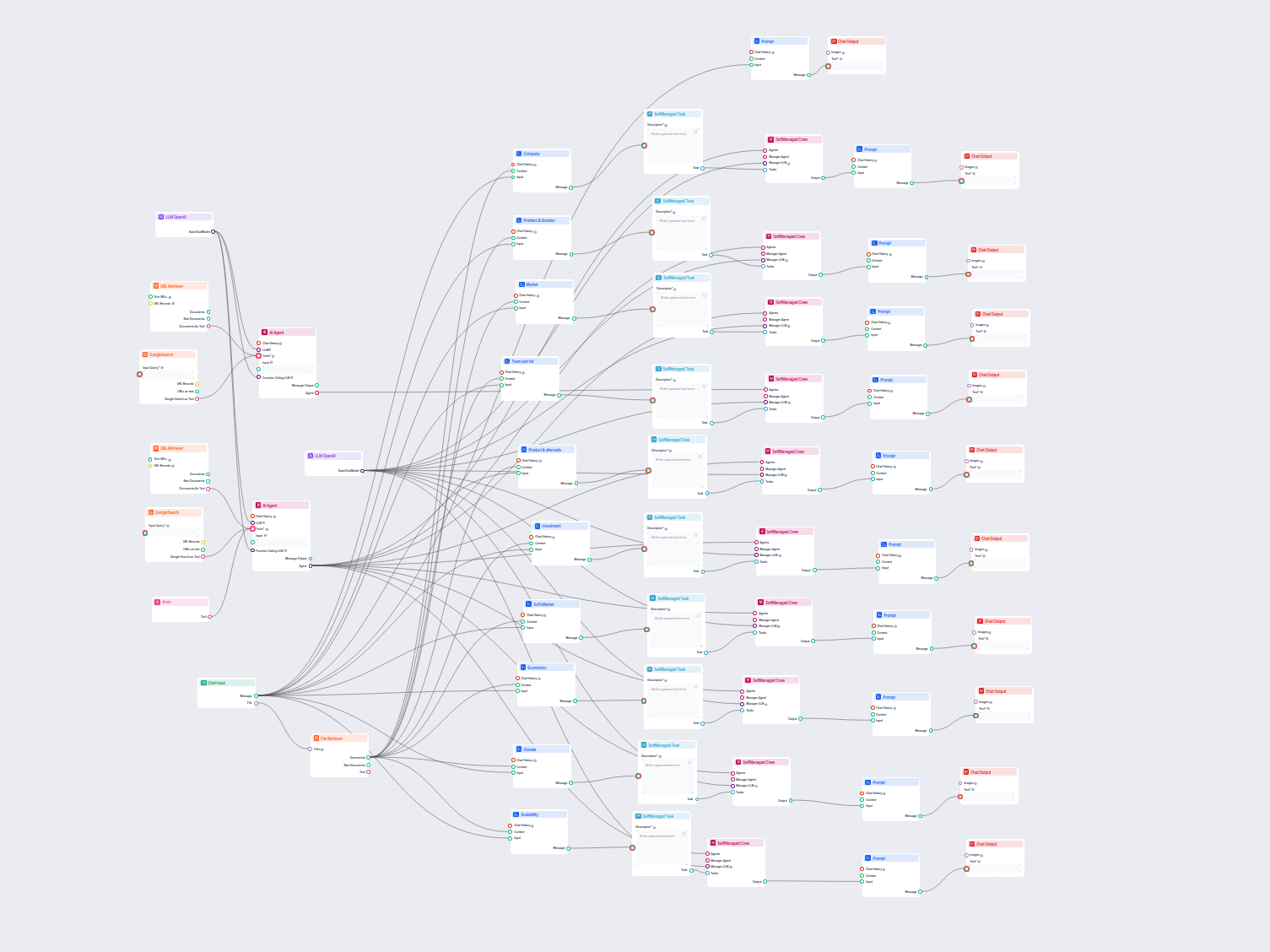
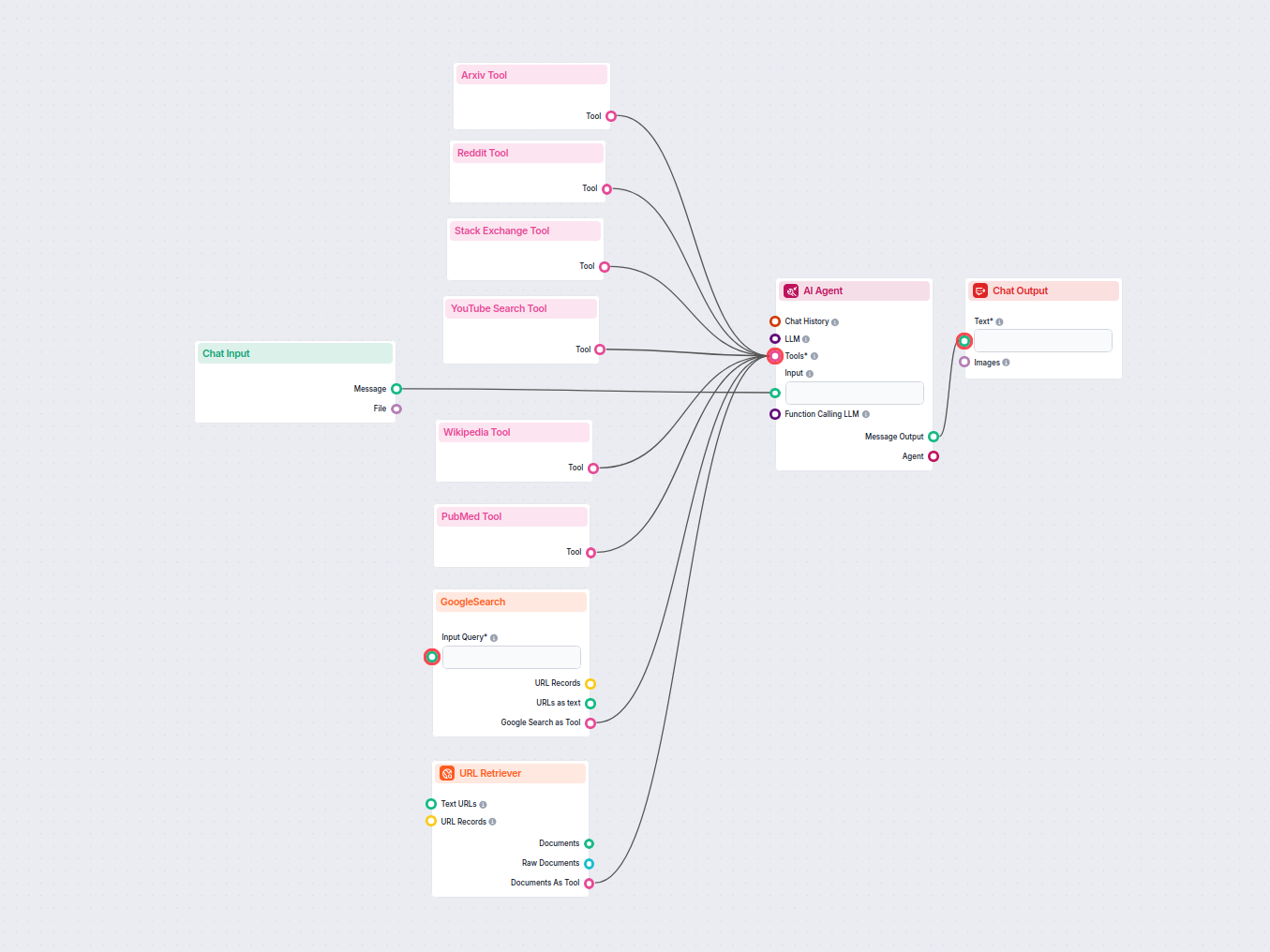
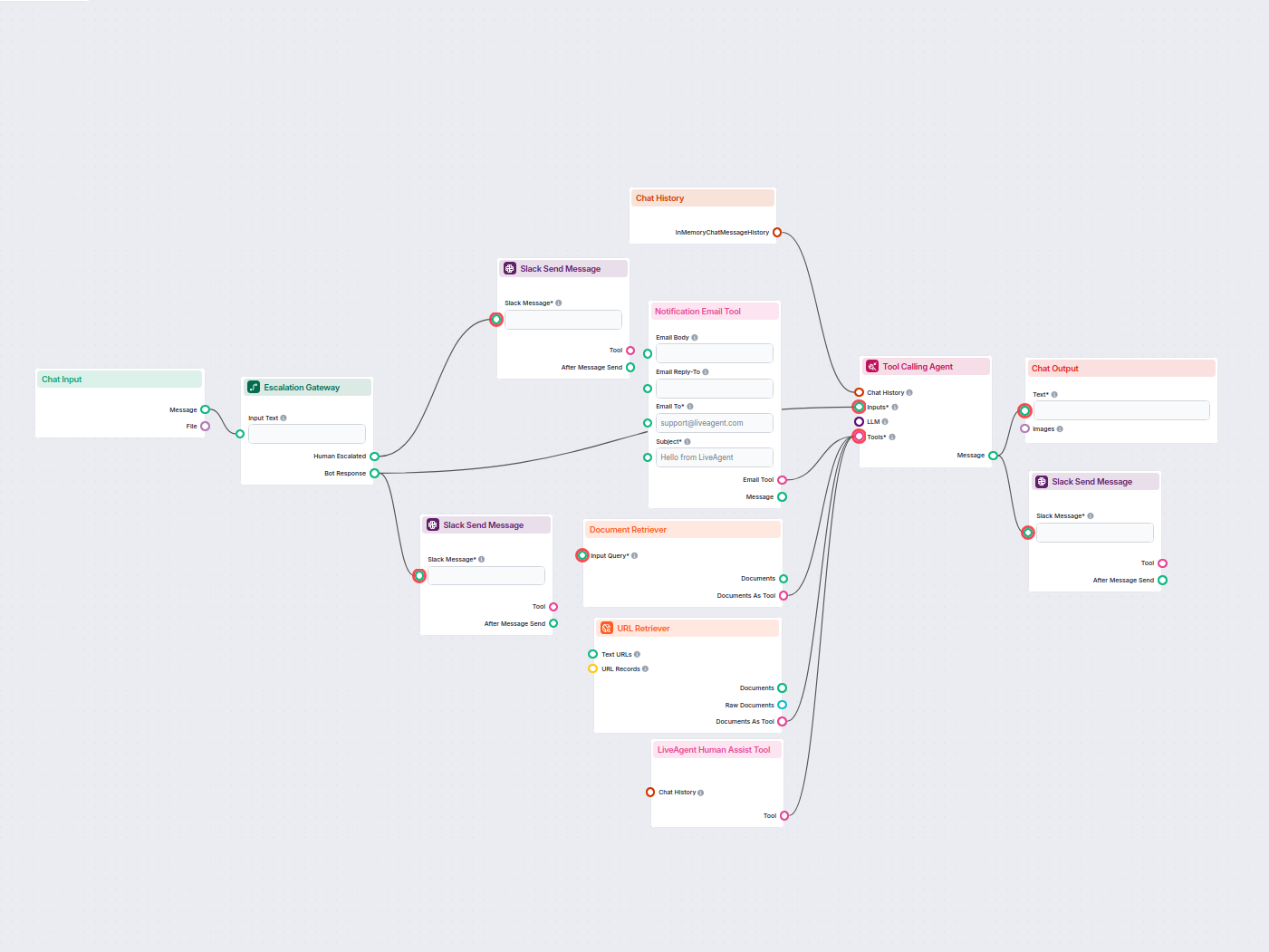
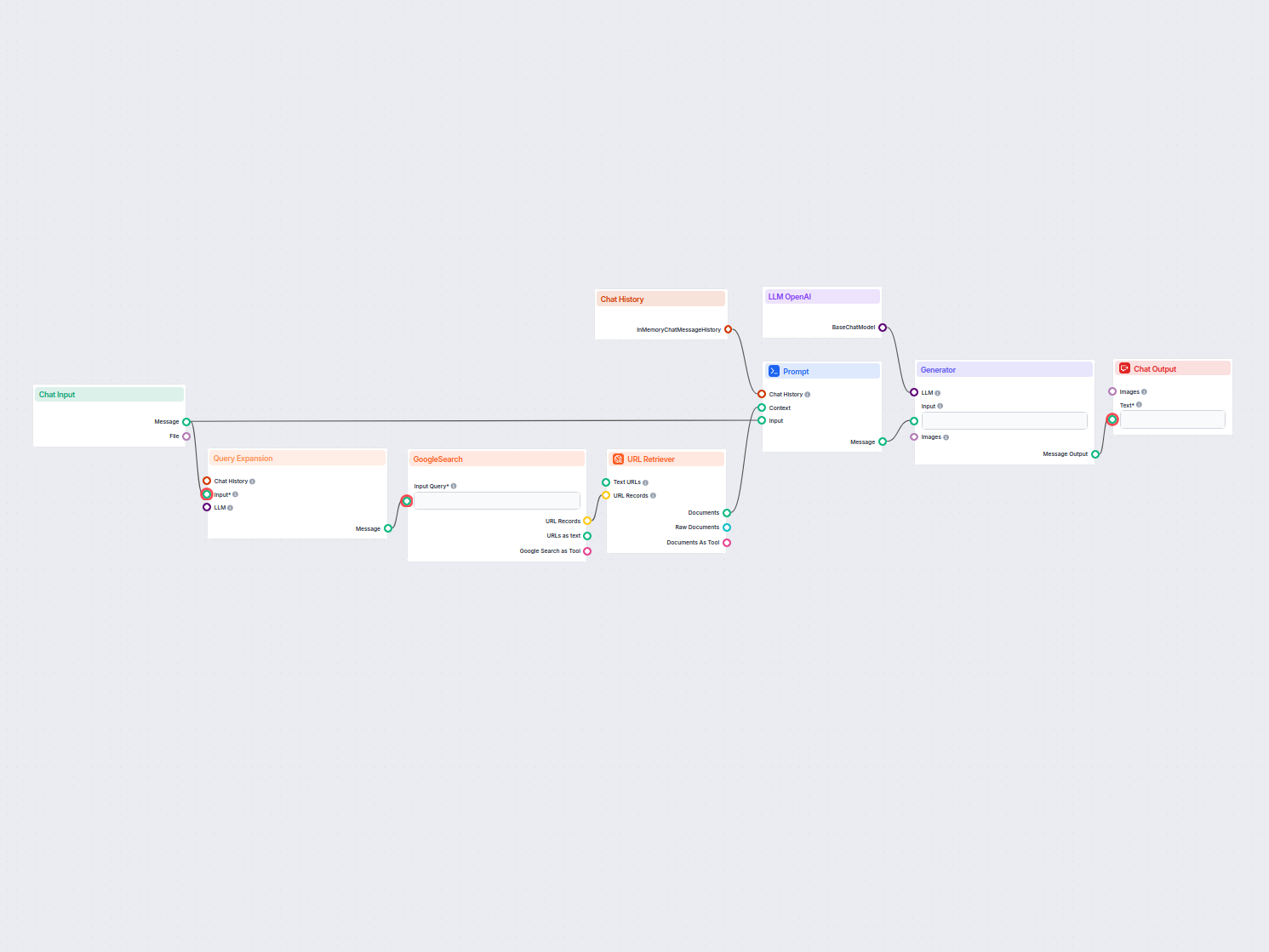
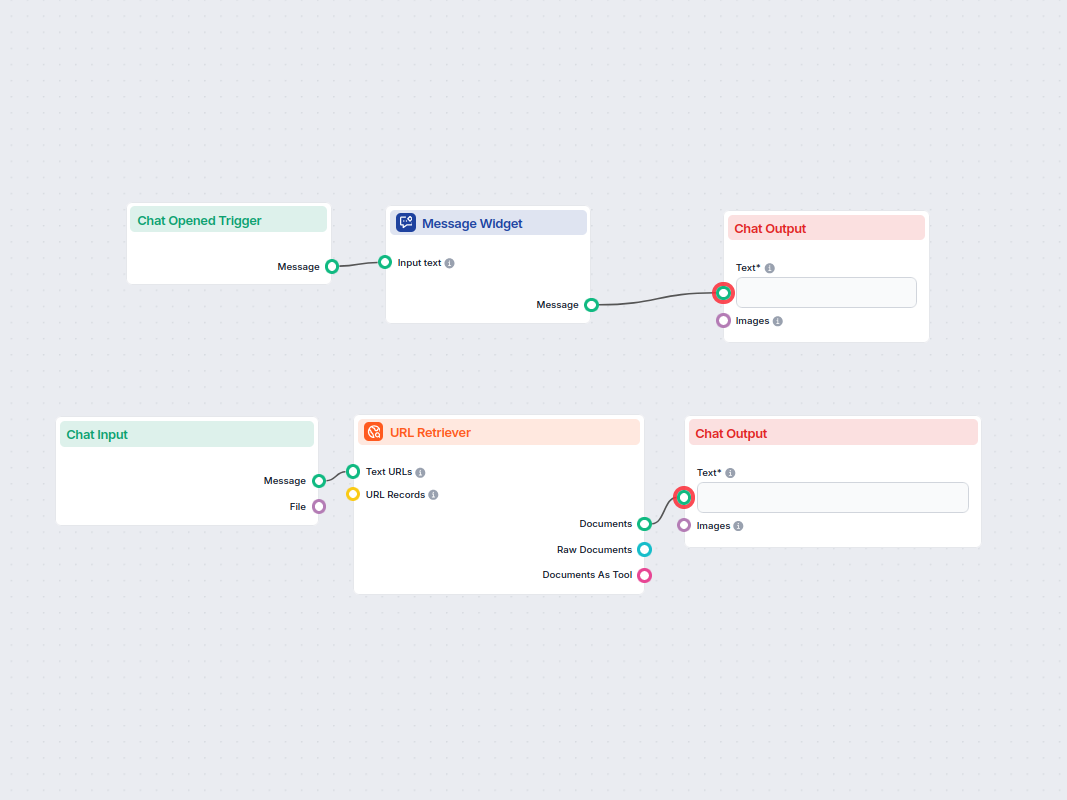
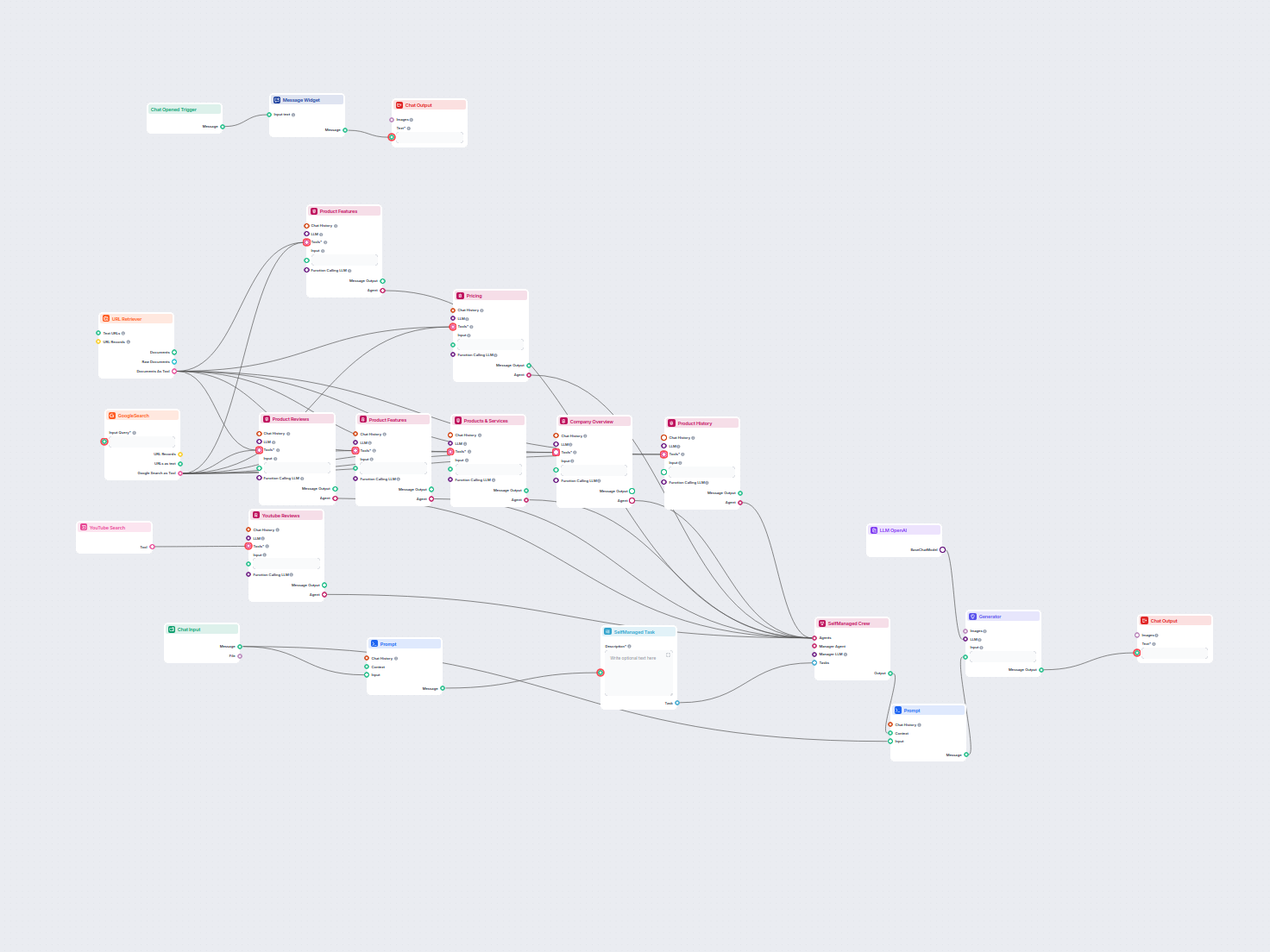
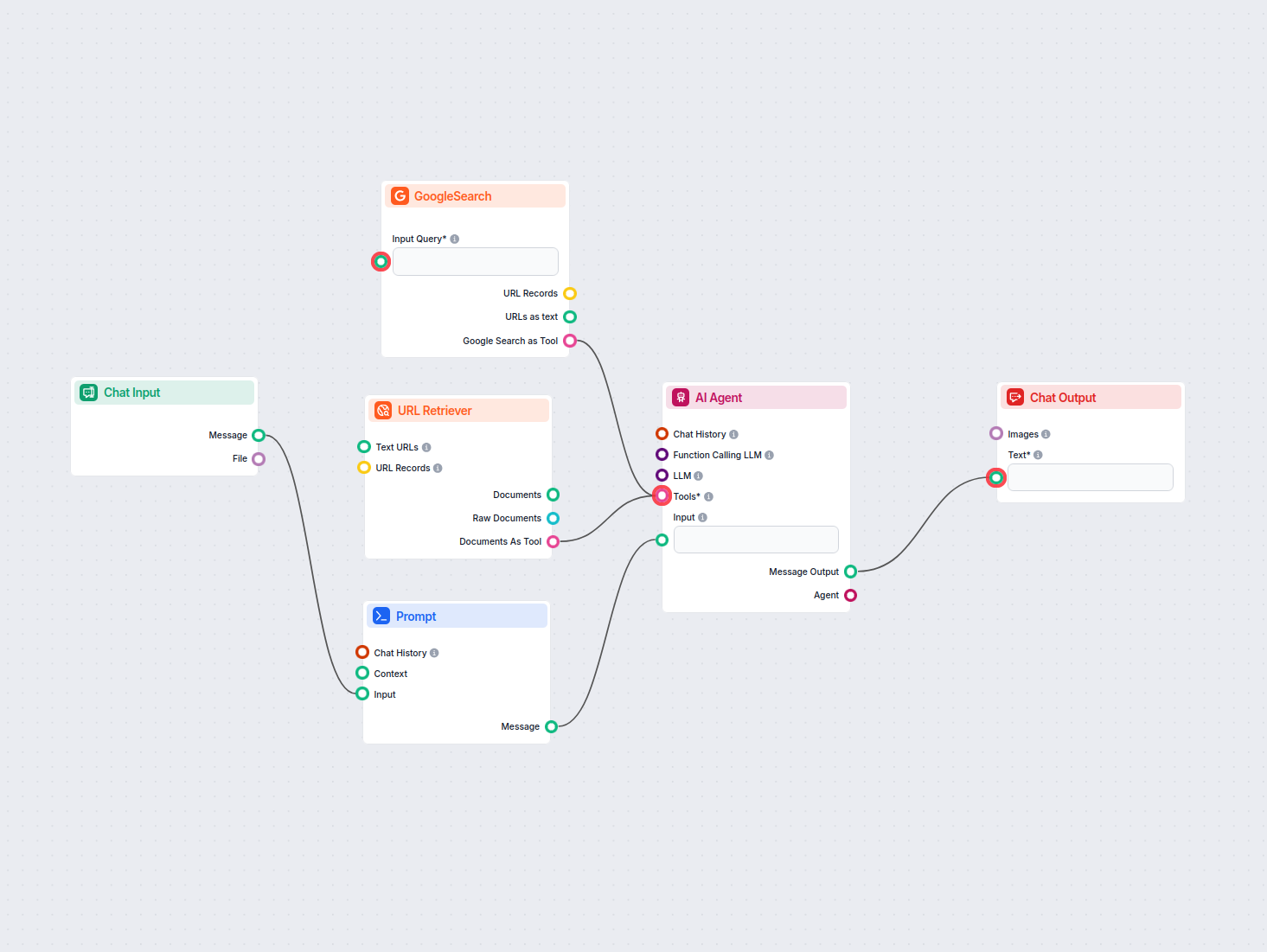
Exemplos de modelos de fluxo usando o componente Recuperador de URL
Para ajudá-lo a começar rapidamente, preparamos vários modelos de fluxo de exemplo que demonstram como usar o componente Recuperador de URL de forma eficaz. Esses modelos apresentam diferentes casos de uso e melhores práticas, tornando mais fácil para você entender e implementar o componente em seus próprios projetos.


















































Perguntas frequentes
- O que o componente Recuperador de URL faz?
O Recuperador de URL busca e processa conteúdo de links da web especificados, tornando texto e metadados de documentos online disponíveis para seu fluxo de trabalho ou agente de IA.
- Ele pode extrair conteúdo de imagens ou PDFs?
Sim, ao habilitar a opção OCR, o componente pode extrair texto de documentos baseados em imagem ou PDFs digitalizados.
- Quais tipos de saída ele fornece?
Ele disponibiliza documentos processados como mensagens de texto, objetos de documento brutos ou como uma ferramenta para fluxos de trabalho de agentes, dependendo da sua configuração.
- Como funciona o cache no Recuperador de URL?
Você pode definir por quanto tempo o conteúdo recuperado será armazenado em cache, reduzindo downloads repetidos e acelerando seus fluxos.
- Posso controlar quais partes de uma página web são extraídas?
Sim, você pode especificar quais títulos, parágrafos ou campos de metadados incluir na saída, permitindo uma extração direcionada.
- Este componente é adequado para criar bots de conhecimento ou automações de dados web?
Com certeza. O Recuperador de URL é essencial para qualquer automação ou chatbot que precise ler, processar ou resumir conteúdo da web em tempo real.
Experimente o Recuperador de URL do FlowHunt
Impulsione seus fluxos de trabalho integrando conteúdo da web em tempo real. Extraia, processe e utilize dados de URLs com facilidade.
Saiba mais