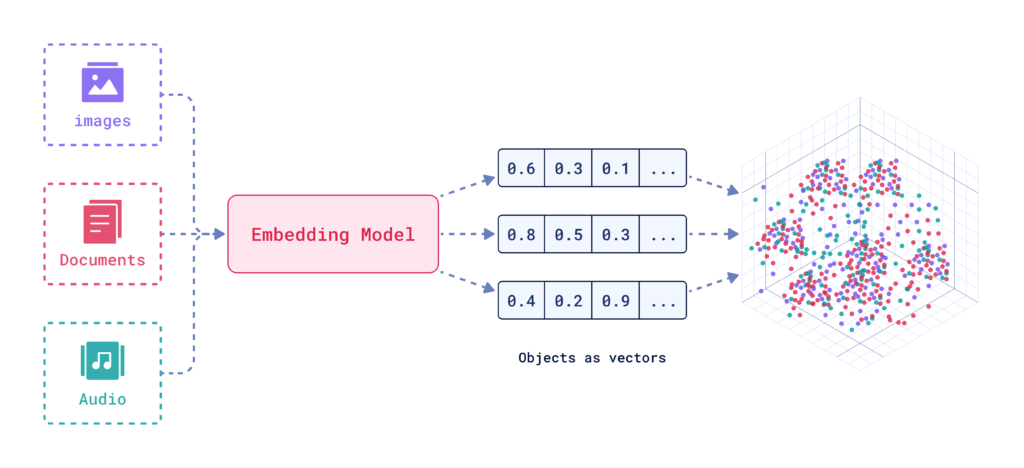
Vetor de Embedding
Um vetor de embedding representa numericamente dados em um espaço multidimensional, permitindo que sistemas de IA capturem relações semânticas para tarefas como classificação, agrupamento e recomendações.
Um vetor de embedding é uma representação numérica densa de dados, onde cada elemento é mapeado para um ponto em um espaço multidimensional. Esse mapeamento é projetado para capturar informações semânticas e relações contextuais entre diferentes pontos de dados. Pontos de dados semelhantes são posicionados mais próximos nesse espaço, facilitando tarefas como classificação, agrupamento e recomendação.
Definindo Vetores de Embedding
Vetores de embedding são essencialmente arrays de números que encapsulam as propriedades intrínsecas e as relações dos dados que representam. Ao traduzir tipos de dados complexos para esses vetores, sistemas de IA podem realizar várias operações de forma mais eficiente.
Importância e Aplicações
Vetores de embedding são fundamentais para muitas aplicações de IA e Aprendizado de Máquina. Eles simplificam a representação de dados de alta dimensão, tornando mais fácil analisar e interpretar.
1. Processamento de Linguagem Natural (PLN)
- Embeddings de Palavras: Técnicas como Word2Vec e GloVe convertem palavras individuais em vetores, capturando relações semânticas e informações contextuais.
- Embeddings de Sentenças: Modelos como Universal Sentence Encoder (USE) geram vetores para sentenças inteiras, encapsulando seu significado geral e contexto.
- Embeddings de Documentos: Técnicas como Doc2Vec representam documentos inteiros como vetores, capturando o conteúdo semântico e o contexto.
2. Processamento de Imagens
- Embeddings de Imagem: Redes neurais convolucionais (CNNs) e modelos pré-treinados como ResNet geram vetores para imagens, capturando diferentes características visuais para tarefas como classificação e detecção de objetos.
3. Sistemas de Recomendação
- Embeddings de Usuário: Esses vetores representam preferências e comportamentos dos usuários, auxiliando em recomendações personalizadas.
- Embeddings de Produto: Vetores que capturam atributos e características de um produto, facilitando comparação e recomendação de produtos.
Como Vetores de Embedding são Criados
A criação de vetores de embedding envolve várias etapas:
- Coleta de Dados: Reúna um grande conjunto de dados relevante ao tipo de embedding que você deseja criar (por exemplo, texto, imagens).
- Pré-processamento: Limpe e prepare os dados removendo ruídos, normalizando textos, redimensionando imagens, etc.
- Seleção de Modelo: Escolha um modelo de rede neural adequado para seus dados.
- Treinamento: Treine o modelo no conjunto de dados, permitindo que ele aprenda padrões e relações.
- Geração de Vetores: À medida que o modelo aprende, ele gera vetores numéricos que representam os dados.
- Avaliação: Avalie a qualidade dos embeddings medindo seu desempenho em tarefas específicas ou por avaliação humana.
Tipos de Vetores de Embedding
- Embeddings de Palavras: Capturam significados de palavras individuais.
- Embeddings de Sentenças: Representam sentenças inteiras.
- Embeddings de Documentos: Representam corpos maiores de texto, como artigos ou livros.
- Embeddings de Imagem: Capturam características visuais de imagens.
- Embeddings de Usuário: Representam preferências e comportamentos dos usuários.
- Embeddings de Produto: Capturam atributos e características de produtos.
Gerando Vetores de Embedding
A biblioteca Transformers da Huggingface oferece modelos de última geração como BERT, RoBERTa e GPT-3. Esses modelos são pré-treinados em grandes conjuntos de dados e fornecem embeddings de alta qualidade que podem ser ajustados para tarefas específicas, tornando-os ideais para criar aplicações robustas de PLN.
Instalando o Huggingface Transformers
Primeiro, certifique-se de que a biblioteca transformers está instalada em seu ambiente Python. Você pode instalá-la usando o pip:
pip install transformers
Carregando um Modelo Pré-treinado
Em seguida, carregue um modelo pré-treinado do hub de modelos da Huggingface. Para este exemplo, usaremos o BERT.
from transformers import BertModel, BertTokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
Tokenizando o Texto
Tokenize seu texto de entrada para prepará-lo para o modelo.
inputs = tokenizer("Hello, Huggingface!", return_tensors='pt')
Gerando Vetores de Embedding
Passe o texto tokenizado pelo modelo para obter os embeddings.
outputs = model(**inputs)
embedding_vectors = outputs.last_hidden_state
4. Exemplo: Gerando Vetores de Embedding com BERT
Aqui está um exemplo completo demonstrando as etapas mencionadas acima:
from transformers import BertModel, BertTokenizer
# Carregar o modelo BERT pré-treinado e o tokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
# Tokenizar o texto de entrada
text = "Hello, Huggingface!"
inputs = tokenizer(text, return_tensors='pt')
# Gerar vetores de embedding
outputs = model(**inputs)
embedding_vectors = outputs.last_hidden_state
print(embedding_vectors)
Dicas e Boas Práticas
- Use GPU: Para grandes conjuntos de dados, utilize aceleração por GPU para agilizar a geração de embeddings.
- Processamento em Lote: Processe múltiplas sentenças em lotes para melhorar a eficiência.
- Ajuste Fino de Modelos: Faça fine-tuning em modelos pré-treinados com seu conjunto de dados específico para obter melhor desempenho.
Armadilhas Comuns e Solução de Problemas
- Problemas de Memória: Se encontrar erros de memória, tente reduzir o tamanho do lote ou usar um modelo mais eficiente em memória.
- Erros de Tokenização: Certifique-se de que seu texto está corretamente tokenizado para evitar incompatibilidades de formato.
- Compatibilidade de Modelos: Verifique se o tokenizer e o modelo são compatíveis entre si.
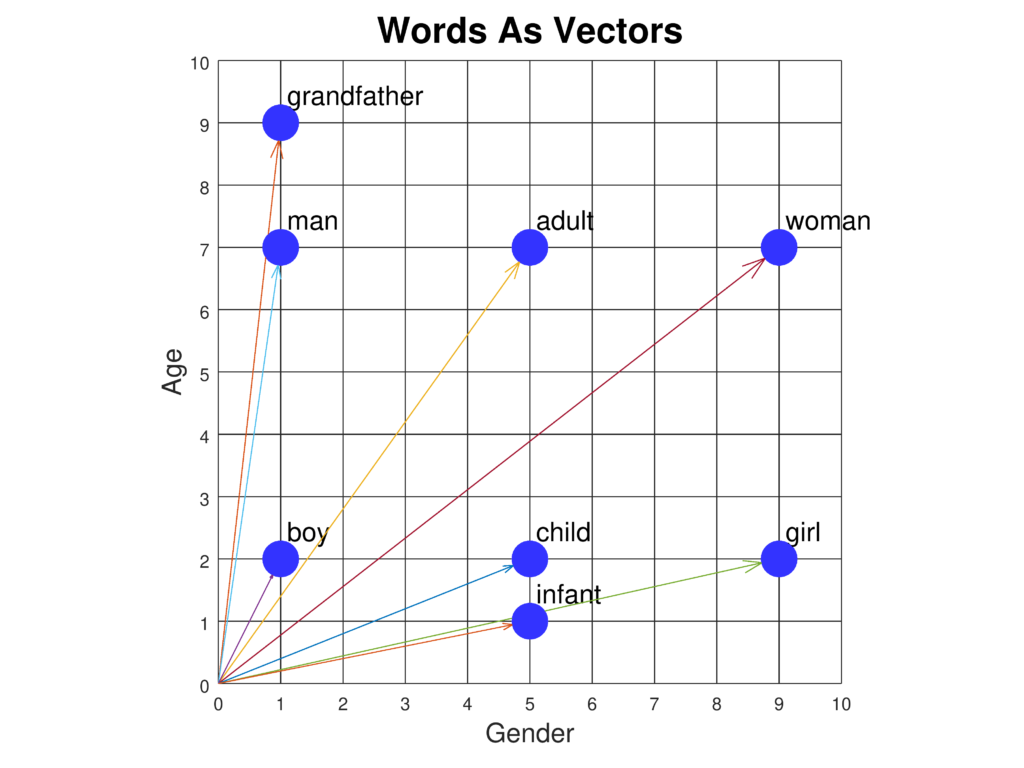
Visualização de Vetores de Embedding
Técnicas de Redução de Dimensionalidade
SNE (Stochastic Neighbor Embedding)
SNE é um método inicial de redução de dimensionalidade, desenvolvido por Geoffrey Hinton e Sam Roweis. Ele calcula similaridades pares no espaço de alta dimensão e tenta preservar essas similaridades em um espaço de menor dimensão.
t-SNE (t-distributed Stochastic Neighbor Embedding)
Uma melhoria sobre o SNE, o t-SNE é amplamente utilizado para visualizar dados de alta dimensão. Ele minimiza a divergência entre duas distribuições: uma representando similaridades pares no espaço original e outra no espaço reduzido, usando uma distribuição t de Student de cauda pesada.
UMAP (Uniform Manifold Approximation and Projection)
UMAP é uma técnica mais recente que oferece computação mais rápida e melhor preservação da estrutura global dos dados em comparação ao t-SNE. Ela constrói um grafo de alta dimensão e otimiza um grafo de baixa dimensão para que sejam estruturalmente o mais semelhantes possível.
Ferramentas e Bibliotecas
Diversas ferramentas e bibliotecas facilitam a visualização de vetores de embedding:
- Matplotlib e Seaborn: Comumente usadas para plotagem e visualização de dados em Python.
- t-SNE em Python: Disponível em bibliotecas como Scikit-learn e TensorFlow.
- UMAP: Implementado como uma biblioteca independente em Python.
Perguntas frequentes
- O que é um vetor de embedding?
Um vetor de embedding é uma representação numérica densa de dados, mapeando cada ponto de dado para uma posição em um espaço multidimensional para capturar relações semânticas e contextuais.
- Como os vetores de embedding são usados em IA?
Vetores de embedding são fundamentais em IA para simplificar dados complexos, possibilitando tarefas como classificação de texto, reconhecimento de imagens e recomendações personalizadas.
- Como posso gerar vetores de embedding?
Vetores de embedding podem ser gerados usando modelos pré-treinados como o BERT da biblioteca Huggingface Transformers. Ao tokenizar seus dados e passá-los por esses modelos, você obtém embeddings de alta qualidade para análise posterior.
- Quais são algumas técnicas para visualizar vetores de embedding?
Técnicas de redução de dimensionalidade como t-SNE e UMAP são comumente usadas para visualizar vetores de embedding de alta dimensão, ajudando a interpretar e analisar padrões nos dados.
Construa Soluções de IA com o FlowHunt
Comece a criar suas próprias ferramentas de IA e chatbots com a plataforma no-code do FlowHunt. Transforme suas ideias em Fluxos automatizados com facilidade.
Saiba mais