Explicabilidade
A Explicabilidade em IA torna as decisões da IA transparentes e compreensíveis, promovendo confiança, atendendo a regulamentações, reduzindo vieses e otimizando modelos por meio de métodos como LIME e SHAP.
Explicabilidade em IA refere-se à capacidade de compreender e interpretar as decisões e previsões feitas por sistemas de inteligência artificial (IA). À medida que os algoritmos de IA e aprendizado de máquina se tornam cada vez mais complexos, especialmente com o avanço do deep learning e das redes neurais, eles frequentemente operam como “caixas-pretas”. Isso significa que, mesmo os engenheiros e cientistas de dados que desenvolvem esses modelos, podem não compreender totalmente como entradas específicas levam a saídas específicas. A Explicabilidade em IA busca lançar luz sobre esses processos, tornando os sistemas de IA mais transparentes e seus resultados mais compreensíveis para os humanos.
Por que a Explicabilidade em IA é Importante?
Confiança e Transparência
Para que os sistemas de IA sejam amplamente aceitos e confiáveis, especialmente em áreas críticas como saúde, finanças e sistemas jurídicos, as partes interessadas precisam entender como as decisões são tomadas. Quando um algoritmo de aprendizado de máquina recomenda um tratamento médico ou aprova um pedido de empréstimo, é fundamental que os usuários conheçam a lógica por trás dessas decisões para garantir justiça e construir confiança.
Requisitos Regulatórios
Muitos setores estão sujeitos a marcos regulatórios que exigem transparência nos processos de tomada de decisão. As regulamentações podem exigir que as organizações forneçam explicações para decisões automatizadas, especialmente quando impactam significativamente indivíduos. O não cumprimento pode resultar em consequências legais e perda de confiança dos consumidores.
Identificação e Mitigação de Vieses
Sistemas de IA treinados com dados enviesados podem perpetuar e até amplificar esses vieses. A explicabilidade permite que desenvolvedores e partes interessadas identifiquem decisões injustas ou enviesadas dentro dos modelos de IA. Ao compreender como as decisões são tomadas, as organizações podem tomar medidas para corrigir vieses, garantindo que os sistemas de IA operem de forma justa entre diferentes grupos demográficos.
Melhoria do Desempenho do Modelo
Compreender o funcionamento interno dos modelos de IA permite que cientistas de dados otimizem o desempenho dos modelos. Ao interpretar quais características influenciam as decisões, é possível ajustar o modelo, melhorar a precisão e garantir que ele generalize bem para novos dados.
Como é Alcançada a Explicabilidade em IA?
Alcançar a Explicabilidade em IA envolve uma combinação entre projetar modelos interpretáveis e aplicar técnicas para interpretar modelos complexos de forma pós-hoc.
Interpretabilidade vs. Explicabilidade
- Interpretabilidade refere-se ao grau em que um ser humano pode entender a causa de uma decisão feita por um sistema de IA.
- Explicabilidade vai além, fornecendo uma descrição explícita dos fatores e raciocínios que levaram a uma decisão.
Embora ambos os conceitos estejam relacionados, a interpretabilidade foca na transparência do próprio modelo, enquanto a explicabilidade foca em gerar explicações para a saída do modelo.
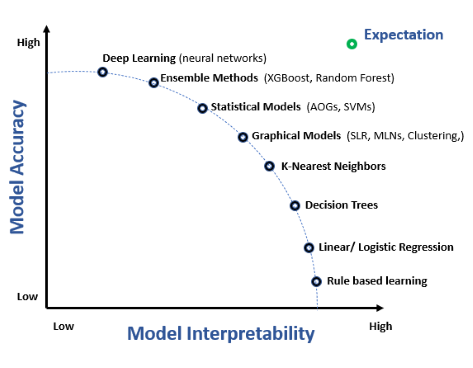
Modelos Interpretáveis
Modelos interpretáveis são inerentemente compreensíveis. Exemplos incluem:
- Regressão Linear: Modelos em que a relação entre as características de entrada e a saída é linear, tornando simples interpretar os coeficientes como a influência de cada característica.
- Árvores de Decisão: Representações visuais de decisões, onde cada nó representa uma característica e os ramos representam regras de decisão.
- Sistemas Baseados em Regras: Sistemas que utilizam um conjunto de regras compreensíveis para humanos na tomada de decisões.
Esses modelos sacrificam um pouco do poder preditivo em prol da transparência, mas são valiosos quando a explicabilidade é crucial.
Explicações Pós-Hoc
Para modelos complexos como redes neurais profundas, que são menos interpretáveis, utilizam-se explicações pós-hoc. Essas técnicas analisam o comportamento do modelo após ele fazer uma previsão.
Métodos Independentes de Modelo
Esses métodos podem ser aplicados a qualquer tipo de modelo sem exigir acesso à sua estrutura interna.
Explicações Locais Independentes de Modelo (LIME)
LIME é uma técnica popular que explica a previsão de qualquer classificador, aproximando-a localmente com um modelo interpretável. Para uma determinada previsão, o LIME perturba levemente os dados de entrada e observa as mudanças na saída para determinar quais características mais influenciam a decisão.
Explicações Aditivas de Shapley (SHAP)
Os valores SHAP baseiam-se na teoria dos jogos cooperativos e fornecem uma medida unificada da importância de cada característica. Eles quantificam a contribuição de cada característica para a previsão, considerando todas as possíveis combinações de características.
Explicações Globais vs. Locais
- Explicações Globais: Oferecem uma compreensão geral do comportamento do modelo em todos os pontos de dados.
- Explicações Locais: Focam em uma única previsão, explicando por que o modelo tomou uma decisão específica para um determinado caso.
Pesquisas sobre Explicabilidade em IA
A explicabilidade em IA tem recebido atenção significativa à medida que os sistemas de IA se integram cada vez mais aos processos de tomada de decisão humana. Aqui estão alguns artigos científicos recentes que abordam esse tema crucial:
Explainable AI Improves Task Performance in Human-AI Collaboration (Publicado em: 2024-06-12)
Autores: Julian Senoner, Simon Schallmoser, Bernhard Kratzwald, Stefan Feuerriegel, Torbjørn Netland
Este artigo explora o impacto da IA explicável na melhoria do desempenho de tarefas durante a colaboração humano-IA. Os autores argumentam que a IA tradicional opera como uma caixa-preta, tornando difícil para os humanos validarem as previsões da IA com base em seu próprio conhecimento. Ao introduzir a IA explicável, especificamente por meio de mapas de calor visuais, o estudo encontrou uma melhoria no desempenho das tarefas. Dois experimentos foram conduzidos envolvendo trabalhadores de fábrica e radiologistas, demonstrando uma redução significativa nas taxas de erro ao usar IA explicável. Esta pesquisa destaca o potencial da IA explicável para melhorar a precisão das decisões em tarefas do mundo real. Leia mais“Weak AI” is Likely to Never Become “Strong AI”, So What is its Greatest Value for Us? (Publicado em: 2021-03-29)
Autor: Bin Liu
Este artigo aborda as controvérsias em andamento sobre as capacidades e o potencial futuro da IA. Diferencia entre “IA fraca” e “IA forte” e argumenta que, embora a IA forte possa não ser alcançável, a IA fraca possui valor substancial. O autor aprofunda-se nos critérios para classificar pesquisas em IA e discute as implicações sociais das capacidades atuais da IA. Este trabalho fornece uma perspectiva filosófica sobre o papel da IA na sociedade. Leia maisUnderstanding Mental Models of AI through Player-AI Interaction (Publicado em: 2021-03-30)
Autores: Jennifer Villareale, Jichen Zhu
Este estudo investiga como indivíduos desenvolvem modelos mentais de sistemas de IA por meio de interações em jogos baseados em IA. Os autores propõem que essas interações oferecem insights valiosos sobre a evolução dos modelos mentais dos usuários de IA. Um estudo de caso é apresentado para destacar as vantagens do uso de jogos no estudo da IA explicável, sugerindo que tais interações podem aprimorar a compreensão dos usuários sobre sistemas de IA.From Explainable to Interactive AI: A Literature Review on Current Trends in Human-AI Interaction (Publicado em: 2024-05-23)
Autores: Muhammad Raees, Inge Meijerink, Ioanna Lykourentzou, Vassilis-Javed Khan, Konstantinos Papangelis
Esta revisão de literatura examina a transição da IA explicável para a IA interativa, enfatizando a importância do envolvimento humano no desenvolvimento e operação de sistemas de IA. O artigo revisa tendências atuais e preocupações sociais sobre a interação humano-IA, destacando a necessidade de sistemas de IA que sejam tanto explicáveis quanto interativos. Esta revisão abrangente fornece um roteiro para pesquisas futuras na área.
Perguntas frequentes
- O que é Explicabilidade em IA?
A Explicabilidade em IA é a capacidade de compreender e interpretar como sistemas de IA tomam decisões e fazem previsões. Ela torna os processos internos da IA transparentes e ajuda os usuários a confiar e validar os resultados gerados pela IA.
- Por que a explicabilidade é importante em IA?
A explicabilidade garante que os sistemas de IA sejam transparentes, confiáveis e estejam em conformidade com regulamentações. Ela ajuda a identificar e mitigar vieses, melhora o desempenho do modelo e permite que os usuários compreendam e confiem nas decisões da IA, especialmente em áreas críticas como saúde e finanças.
- Quais técnicas são usadas para alcançar a explicabilidade em IA?
Técnicas comuns incluem modelos interpretáveis (como regressão linear e árvores de decisão) e métodos de explicação pós-hoc, como LIME e SHAP, que fornecem insights sobre decisões de modelos complexos.
- Qual a diferença entre interpretabilidade e explicabilidade?
Interpretabilidade refere-se a quão bem um humano pode entender a causa de uma decisão tomada por um modelo de IA. Explicabilidade vai além, fornecendo razões detalhadas e contexto para as saídas do modelo, tornando explícita a lógica por trás das decisões.
- Como a explicabilidade ajuda na redução de vieses em IA?
A explicabilidade permite que as partes interessadas examinem como os modelos de IA tomam decisões, ajudando a identificar e corrigir quaisquer vieses presentes nos dados ou na lógica do modelo, garantindo assim resultados mais justos e equitativos.
Pronto para criar sua própria IA?
Chatbots inteligentes e ferramentas de IA em um só lugar. Conecte blocos intuitivos para transformar suas ideias em Fluxos automatizados.
Saiba mais