Kubeflow
Kubeflow é uma plataforma de ML de código aberto construída sobre Kubernetes que simplifica a implantação, o gerenciamento e a escalabilidade de fluxos de trabalho de machine learning em diferentes infraestruturas.
A missão do Kubeflow é tornar o dimensionamento de modelos de ML e sua implantação em produção o mais simples possível, utilizando as capacidades do Kubernetes. Isso inclui implantações fáceis, repetíveis e portáteis em diferentes infraestruturas. A plataforma começou como um método para executar tarefas do TensorFlow no Kubernetes e desde então evoluiu para um framework versátil que suporta uma ampla gama de frameworks e ferramentas de ML.
Conceitos e Componentes Principais do Kubeflow
1. Kubeflow Pipelines
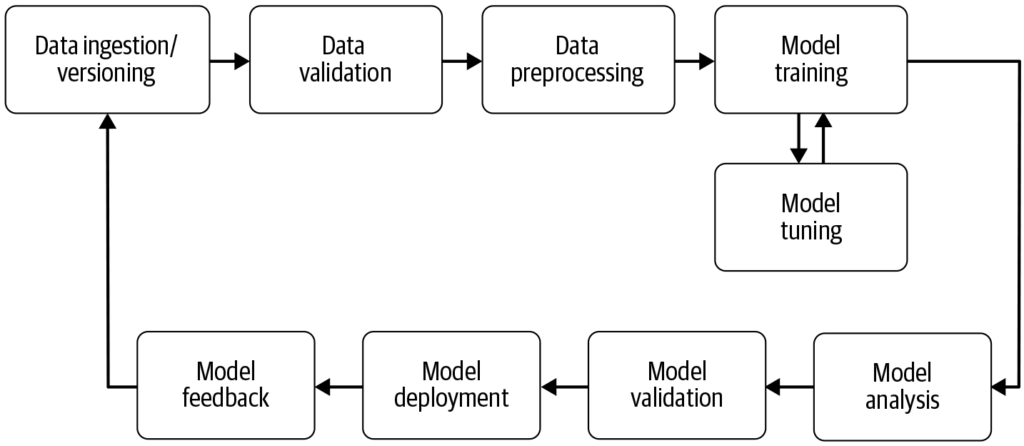
O Kubeflow Pipelines é um componente central que permite aos usuários definir e executar fluxos de trabalho de ML como Grafos Acíclicos Direcionados (DAGs). Fornece uma plataforma para construir fluxos de trabalho de machine learning portáteis e escaláveis usando Kubernetes. O componente Pipelines consiste em:
- Interface do Usuário (UI): Uma interface web para gerenciar e rastrear experimentos, tarefas e execuções.
- SDK: Um conjunto de pacotes Python para definir e manipular pipelines e componentes.
- Motor de Orquestração: Agenda e gerencia fluxos de trabalho de ML com múltiplas etapas.
Esses recursos permitem que cientistas de dados automatizem o processo de ponta a ponta de pré-processamento de dados, treinamento de modelos, avaliação e implantação, promovendo reprodutibilidade e colaboração em projetos de ML. A plataforma suporta a reutilização de componentes e pipelines, agilizando assim a criação de soluções de ML.
2. Painel Central
O Painel Central do Kubeflow serve como a interface principal para acessar o Kubeflow e seu ecossistema. Ele agrega as interfaces de usuário de várias ferramentas e serviços dentro do cluster, fornecendo um ponto de acesso unificado para gerenciar atividades de machine learning. O painel oferece funcionalidades como autenticação de usuários, isolamento multiusuário e gerenciamento de recursos.
3. Jupyter Notebooks
O Kubeflow integra-se com Jupyter Notebooks, oferecendo um ambiente interativo para exploração de dados, experimentação e desenvolvimento de modelos. Os notebooks suportam várias linguagens de programação e permitem que os usuários criem e executem fluxos de trabalho de ML de forma colaborativa.
4. Treinamento e Serviço de Modelos
- Training Operator: Suporta treinamento distribuído de modelos de ML usando frameworks populares como TensorFlow, PyTorch e XGBoost. Aproveita a escalabilidade do Kubernetes para treinar modelos de forma eficiente em clusters de máquinas.
- KFServing: Fornece uma plataforma de inferência sem servidor para implantar modelos de ML treinados. Simplifica a implantação e escalabilidade de modelos, suportando frameworks como TensorFlow, PyTorch e scikit-learn.
5. Gerenciamento de Metadados
O Kubeflow Metadata é um repositório centralizado para rastrear e gerenciar metadados associados a experimentos de ML, execuções e artefatos. Ele garante reprodutibilidade, colaboração e governança em projetos de ML ao fornecer uma visão consistente dos metadados de ML.
6. Katib para Ajuste de Hiperparâmetros
Katib é um componente de aprendizado de máquina automatizado (AutoML) dentro do Kubeflow. Ele suporta ajuste de hiperparâmetros, parada antecipada e busca de arquitetura neural, otimizando o desempenho de modelos de ML ao automatizar a busca por hiperparâmetros ideais.
Casos de Uso e Exemplos
O Kubeflow é utilizado por organizações de diversos setores para agilizar suas operações de ML. Alguns casos de uso comuns incluem:
- Preparação e Exploração de Dados: Usando Jupyter Notebooks e Kubeflow Pipelines para pré-processar e analisar grandes conjuntos de dados de forma eficiente.
- Treinamento de Modelos em Escala: Aproveitando a escalabilidade do Kubernetes para treinar modelos complexos em grandes volumes de dados, melhorando a acurácia e reduzindo o tempo de treinamento.
- Automatização de Fluxos de ML: Automatizando tarefas repetitivas de ML com Kubeflow Pipelines, aumentando a produtividade e permitindo que cientistas de dados foquem no desenvolvimento e otimização de modelos.
- Serviço de Modelos em Tempo Real: Implantando modelos como serviços escaláveis e prontos para produção usando KFServing, garantindo previsões de baixa latência para aplicações em tempo real.
Estudo de Caso: Spotify
O Spotify utiliza o Kubeflow para capacitar seus cientistas de dados e engenheiros no desenvolvimento e implantação de modelos de machine learning em escala. Ao integrar o Kubeflow à sua infraestrutura existente, o Spotify otimizou seus fluxos de trabalho de ML, reduzindo o tempo de lançamento de novos recursos e melhorando a eficiência de seus sistemas de recomendação.
Benefícios de Usar o Kubeflow
Escalabilidade e Portabilidade
O Kubeflow permite que organizações escalem seus fluxos de trabalho de ML conforme necessário e os implantem em diferentes infraestruturas, incluindo ambientes locais, em nuvem e híbridos. Essa flexibilidade ajuda a evitar o aprisionamento a fornecedores e possibilita transições suaves entre diferentes ambientes computacionais.
Reprodutibilidade e Rastreamento de Experimentos
A arquitetura baseada em componentes do Kubeflow facilita a reprodução de experimentos e modelos. Ele fornece ferramentas para versionar e rastrear conjuntos de dados, códigos e parâmetros de modelos, garantindo consistência e colaboração entre cientistas de dados.
Extensibilidade e Integração
O Kubeflow foi projetado para ser extensível, permitindo integração com diversas outras ferramentas e serviços, incluindo plataformas de ML baseadas em nuvem. As organizações podem personalizar o Kubeflow com componentes adicionais, aproveitando ferramentas e fluxos de trabalho já existentes para potencializar seu ecossistema de ML.
Redução da Complexidade Operacional
Ao automatizar diversas tarefas associadas à implantação e ao gerenciamento de fluxos de trabalho de ML, o Kubeflow libera cientistas de dados e engenheiros para focarem em tarefas de maior valor, como o desenvolvimento e otimização de modelos, gerando ganhos em produtividade e eficiência.
Melhor Utilização de Recursos
A integração do Kubeflow com o Kubernetes permite uma utilização mais eficiente dos recursos, otimizando a alocação de hardware e reduzindo custos relacionados à execução de cargas de trabalho de ML.
Como Começar com o Kubeflow
Para começar a usar o Kubeflow, os usuários podem implantá-lo em um cluster Kubernetes, seja local ou na nuvem. Existem diversos guias de instalação disponíveis, atendendo a diferentes níveis de experiência e necessidades de infraestrutura. Para quem está começando com Kubernetes, serviços gerenciados como o Vertex AI Pipelines oferecem uma entrada mais acessível, cuidando do gerenciamento da infraestrutura e permitindo que os usuários foquem em construir e executar fluxos de trabalho de ML.
Esta exploração detalhada do Kubeflow fornece insights sobre suas funcionalidades, benefícios e casos de uso, oferecendo uma compreensão abrangente para organizações que buscam aprimorar suas capacidades em machine learning.
Entendendo o Kubeflow: Um Kit de Ferramentas de Machine Learning no Kubernetes
O Kubeflow é um projeto de código aberto projetado para facilitar a implantação, orquestração e gerenciamento de modelos de machine learning no Kubernetes. Ele fornece uma stack completa de ponta a ponta para fluxos de trabalho de machine learning, tornando mais fácil para cientistas de dados e engenheiros construírem, implantarem e gerenciarem modelos de machine learning escaláveis.
Artigos e Recursos Selecionados
Deployment of ML Models using Kubeflow on Different Cloud Providers
Autores: Aditya Pandey et al. (2022)
Este artigo explora a implantação de modelos de machine learning usando o Kubeflow em várias plataformas de nuvem. O estudo fornece informações sobre o processo de configuração, modelos de implantação e métricas de desempenho do Kubeflow, servindo como um guia útil para iniciantes. Os autores destacam as funcionalidades e limitações da ferramenta e demonstram seu uso na criação de pipelines de machine learning ponta a ponta. O artigo tem como objetivo auxiliar usuários com pouca experiência em Kubernetes a aproveitar o Kubeflow para implantação de modelos.
Leia maisCLAIMED, a visual and scalable component library for Trusted AI
Autores: Romeo Kienzler e Ivan Nesic (2021)
Este trabalho foca na integração de componentes de IA confiável com o Kubeflow. Aborda questões como explicabilidade, robustez e justiça em modelos de IA. O artigo apresenta o CLAIMED, um framework de componentes reutilizáveis que incorpora ferramentas como AI Explainability360 e AI Fairness360 em pipelines do Kubeflow. Essa integração facilita o desenvolvimento de aplicações de machine learning de nível de produção usando editores visuais como ElyraAI.
Leia maisJet energy calibration with deep learning as a Kubeflow pipeline
Autores: Daniel Holmberg et al. (2023)
O Kubeflow é utilizado para criar um pipeline de machine learning para calibrar medições de energia de jatos no experimento CMS. Os autores empregam modelos de deep learning para melhorar a calibração da energia dos jatos, mostrando como as capacidades do Kubeflow podem ser ampliadas para aplicações em física de altas energias. O artigo discute a eficácia do pipeline em escalar o ajuste de hiperparâmetros e servir modelos de forma eficiente em recursos de nuvem.
Leia mais
Perguntas frequentes
- O que é o Kubeflow?
Kubeflow é uma plataforma de código aberto construída sobre Kubernetes, projetada para simplificar a implantação, o gerenciamento e a escalabilidade de fluxos de trabalho de machine learning. Fornece um conjunto abrangente de ferramentas para todo o ciclo de vida do ML.
- Quais são os principais componentes do Kubeflow?
Os componentes principais incluem Kubeflow Pipelines para orquestração de fluxos de trabalho, um painel central, integração com Jupyter Notebooks, treinamento e serviço de modelos distribuídos, gerenciamento de metadados e Katib para ajuste de hiperparâmetros.
- Como o Kubeflow melhora a escalabilidade e a reprodutibilidade?
Aproveitando o Kubernetes, o Kubeflow permite cargas de trabalho de ML escaláveis em vários ambientes e fornece ferramentas para rastreamento de experimentos e reutilização de componentes, garantindo reprodutibilidade e colaboração eficiente.
- Quem usa o Kubeflow?
Organizações de diversos setores utilizam o Kubeflow para gerenciar e escalar suas operações de ML. Usuários notáveis como o Spotify integraram o Kubeflow para agilizar o desenvolvimento e a implantação de modelos.
- Como começo a usar o Kubeflow?
Para começar, implante o Kubeflow em um cluster Kubernetes — seja localmente ou na nuvem. Guias de instalação e serviços gerenciados estão disponíveis para auxiliar usuários de todos os níveis de experiência.
Comece a construir com Kubeflow
Descubra como o Kubeflow pode simplificar seus fluxos de trabalho de machine learning no Kubernetes, desde treinamentos escaláveis até implantação automatizada.
Saiba mais