
Pipeline de Machine Learning
Um pipeline de machine learning automatiza as etapas desde a coleta de dados até a implantação do modelo, aumentando a eficiência, reprodutibilidade e escalabilidade em projetos de machine learning.
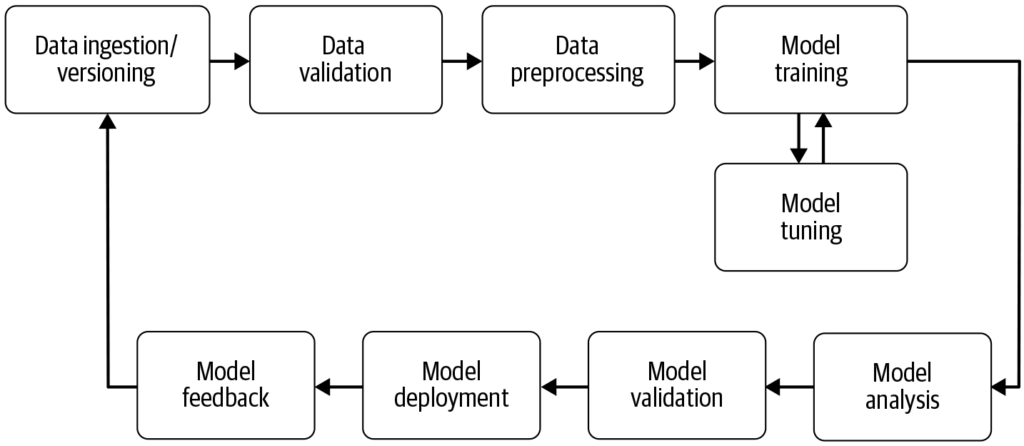
Pipeline de Machine Learning
Um pipeline de machine learning é um fluxo de trabalho automatizado que simplifica o desenvolvimento, treinamento, avaliação e implantação de modelos. Ele aumenta a eficiência, reprodutibilidade e escalabilidade, facilitando tarefas desde a coleta de dados até a implantação e manutenção do modelo.
Um pipeline de machine learning é um fluxo de trabalho automatizado que abrange uma série de etapas envolvidas no desenvolvimento, treinamento, avaliação e implantação de modelos de machine learning. Ele é projetado para simplificar e padronizar os processos necessários para transformar dados brutos em insights acionáveis por meio de algoritmos de machine learning. A abordagem em pipeline permite o manejo eficiente dos dados, treinamento e implantação de modelos, tornando mais fácil gerenciar e escalar operações de machine learning.
Fonte: Building Machine Learning
Componentes de um Pipeline de Machine Learning
Coleta de Dados: A etapa inicial em que os dados são coletados de várias fontes, como bancos de dados, APIs ou arquivos. A coleta de dados é uma prática metódica com o objetivo de adquirir informações relevantes para construir um conjunto de dados consistente e completo para um determinado objetivo de negócio. Esses dados brutos são essenciais para a construção de modelos de machine learning, mas frequentemente requerem pré-processamento para serem úteis. Conforme destacado pela AltexSoft, a coleta de dados envolve o acúmulo sistemático de informações para sustentar análises e tomadas de decisão. Esse processo é crucial, pois estabelece a base para todas as etapas subsequentes do pipeline e, muitas vezes, é contínuo para garantir que os modelos sejam treinados com dados relevantes e atualizados.
Pré-processamento de Dados: Os dados brutos são limpos e transformados em um formato adequado para o treinamento do modelo. As etapas comuns de pré-processamento incluem tratamento de valores ausentes, codificação de variáveis categóricas, escalonamento de características numéricas e divisão dos dados em conjuntos de treino e teste. Essa etapa garante que os dados estejam no formato correto e livres de inconsistências que possam afetar o desempenho do modelo.
Engenharia de Features: Criação de novas features ou seleção das mais relevantes nos dados para melhorar o poder preditivo do modelo. Esta etapa pode exigir conhecimento específico do domínio e criatividade. A engenharia de features é um processo criativo que transforma dados brutos em características significativas que melhor representam o problema e aumentam a performance dos modelos de machine learning.
Seleção de Modelo: O(s) algoritmo(s) de machine learning apropriado(s) são escolhidos com base no tipo de problema (por exemplo, classificação, regressão), características dos dados e requisitos de desempenho. A escolha dos hiperparâmetros também pode ser considerada nesta etapa. Selecionar o modelo correto é fundamental, pois influencia a precisão e a eficiência das previsões.
Treinamento de Modelo: O(s) modelo(s) selecionado(s) são treinados usando o conjunto de dados de treino. Isso envolve aprender os padrões e relações subjacentes nos dados. Modelos pré-treinados também podem ser utilizados em vez de treinar um novo modelo do zero. O treinamento é uma etapa vital onde o modelo aprende com os dados para fazer previsões informadas.
Avaliação de Modelo: Após o treinamento, o desempenho do modelo é avaliado usando um conjunto de teste separado ou por meio de validação cruzada. As métricas de avaliação dependem do problema específico, mas podem incluir acurácia, precisão, recall, F1-score, erro quadrático médio, entre outras. Essa etapa é crucial para garantir que o modelo terá um bom desempenho em dados não vistos.
Implantação de Modelo: Uma vez que um modelo satisfatório é desenvolvido e avaliado, ele pode ser implantado em ambiente de produção para fazer previsões em novos dados. A implantação pode envolver a criação de APIs e integração com outros sistemas. A implantação é a etapa final do pipeline, tornando o modelo acessível para uso no mundo real.
Monitoramento e Manutenção: Após a implantação, é fundamental monitorar continuamente o desempenho do modelo e reentreiná-lo quando necessário, para adaptar-se a mudanças nos padrões dos dados, garantindo que o modelo permaneça preciso e confiável em ambientes reais. Esse processo contínuo assegura que o modelo se mantenha relevante e preciso ao longo do tempo.
Benefícios dos Pipelines de Machine Learning
- Modularização: Os pipelines dividem o processo de machine learning em etapas modulares e bem definidas, facilitando o gerenciamento e manutenção do fluxo de trabalho. Cada componente pode ser desenvolvido, testado e otimizado de forma independente.
- Reprodutibilidade: Ao definir a sequência das etapas e seus parâmetros, os pipelines garantem que todo o processo possa ser recriado exatamente, proporcionando resultados consistentes. Isso é vital para validar e manter o desempenho do modelo ao longo do tempo.
- Eficiência: A automação de tarefas rotineiras como pré-processamento de dados e avaliação de modelos reduz o tempo e os riscos de erro. Isso permite que os cientistas de dados foquem em tarefas mais complexas, como engenharia de features e ajuste de modelos.
- Escalabilidade: Os pipelines podem lidar com grandes volumes de dados e fluxos de trabalho complexos, possibilitando ajustes sem precisar reconfigurar tudo do zero. Essa escalabilidade é essencial para lidar com a crescente quantidade de dados disponível atualmente.
- Experimentação: Eles permitem rápida iteração e otimização ao possibilitar experimentos com diferentes técnicas de pré-processamento de dados, seleção de features e modelos. Essa flexibilidade é crucial para inovação e melhoria contínua.
- Implantação: Os pipelines facilitam a integração dos modelos em ambientes de produção. Isso garante que os modelos possam ser utilizados de forma eficaz em aplicações reais.
- Colaboração: Fluxos de trabalho estruturados e documentados facilitam a colaboração e o engajamento das equipes nos projetos. Isso fomenta um ambiente de conhecimento compartilhado e trabalho em equipe.
- Controle de Versão e Documentação: Com o uso de sistemas de controle de versão, as mudanças no código e configurações do pipeline podem ser rastreadas, garantindo a capacidade de reverter para versões anteriores quando necessário. Isso é essencial para manter um processo de desenvolvimento confiável e transparente.
Casos de Uso dos Pipelines de Machine Learning
Processamento de Linguagem Natural (PLN): Tarefas de PLN geralmente envolvem várias etapas repetíveis, como ingestão de dados, limpeza de texto, tokenização e análise de sentimento. Os pipelines ajudam a modularizar essas etapas, permitindo modificações e atualizações fáceis sem afetar outros componentes.
Manutenção Preditiva: Em indústrias como a manufatura, pipelines podem ser usados para prever falhas de equipamentos analisando dados de sensores, permitindo manutenção proativa e reduzindo o tempo de inatividade.
Finanças: Os pipelines podem automatizar o processamento de dados financeiros para detectar fraudes, avaliar riscos de crédito ou prever preços de ações, aprimorando processos de tomada de decisão.
Saúde: Na área da saúde, pipelines podem processar imagens médicas ou registros de pacientes para auxiliar em diagnósticos ou prever desfechos clínicos, melhorando estratégias de tratamento.
Desafios Associados a Pipelines de Machine Learning
- Qualidade dos Dados: Garantir a qualidade e acessibilidade dos dados é crucial, pois dados ruins podem gerar modelos imprecisos. Isso exige práticas e ferramentas robustas de gestão de dados.
- Complexidade: Projetar e manter pipelines complexos pode ser desafiador, exigindo expertise tanto em ciência de dados quanto em engenharia de software. Essa complexidade pode ser atenuada com o uso de ferramentas e frameworks padronizados.
- Integração: Integrar pipelines de forma transparente com sistemas e fluxos de trabalho existentes requer planejamento e execução cuidadosos. Isso geralmente envolve a colaboração entre cientistas de dados e profissionais de TI.
- Custo: Gerenciar os recursos computacionais e a infraestrutura necessários para pipelines em larga escala pode ser caro. Isso exige planejamento e orçamentação cuidadosos para garantir o uso eficiente dos recursos.
Conexão com IA e Automação
Os pipelines de machine learning são parte fundamental da IA e automação, pois fornecem uma estrutura organizada para automatizar tarefas de machine learning. No contexto da automação de IA, os pipelines garantem que os modelos sejam treinados e implantados de forma eficiente, tornando possível que sistemas de IA, como [chatbots], aprendam e se adaptem a novos dados sem intervenção manual. Essa automação é crucial para escalar aplicações de IA e garantir desempenho consistente e confiável em diversos domínios. Ao utilizar pipelines, as organizações ampliam suas capacidades em IA e asseguram que seus modelos de machine learning permaneçam relevantes e eficazes em ambientes dinâmicos.
Pesquisa sobre Pipeline de Machine Learning
“Deep Pipeline Embeddings for AutoML” de Sebastian Pineda Arango e Josif Grabocka (2023) foca nos desafios de otimizar pipelines de machine learning em AutoML (Automated Machine Learning). Este artigo apresenta uma nova arquitetura neural projetada para capturar interações profundas entre os componentes do pipeline. Os autores propõem embutir pipelines em representações latentes por meio de um mecanismo exclusivo de codificação por componente. Esses embeddings são utilizados em um framework de Otimização Bayesiana para buscar pipelines ótimos. O artigo enfatiza o uso de meta-learning para ajustar os parâmetros da rede de embeddings, demonstrando resultados de ponta em otimização de pipelines em múltiplos conjuntos de dados. Leia mais.
“AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model” de Tien-Dung Nguyen et al. (2020) aborda a avaliação demorada de pipelines de machine learning durante processos de AutoML. O estudo critica métodos tradicionais, como otimizações bayesianas e genéticas, por sua ineficiência. Para resolver isso, os autores apresentam o AVATAR, um modelo substituto que avalia de forma eficiente a validade dos pipelines sem execução. Essa abordagem acelera significativamente a composição e otimização de pipelines complexos ao filtrar rapidamente os inválidos. Leia mais.
“Data Pricing in Machine Learning Pipelines” de Zicun Cong et al. (2021) explora o papel fundamental dos dados em pipelines de machine learning e a necessidade de precificação de dados para facilitar a colaboração entre múltiplos stakeholders. O artigo revisa os avanços mais recentes em precificação de dados no contexto de machine learning, destacando sua importância em várias etapas do pipeline. Apresenta insights sobre estratégias de precificação para coleta de dados de treinamento, treinamento colaborativo de modelos e oferta de serviços de machine learning, ressaltando a formação de um ecossistema dinâmico. Leia mais.
Perguntas frequentes
- O que é um pipeline de machine learning?
Um pipeline de machine learning é uma sequência automatizada de etapas — desde a coleta e pré-processamento de dados até o treinamento, avaliação e implantação do modelo — que simplifica e padroniza o processo de construir e manter modelos de machine learning.
- Quais são os principais componentes de um pipeline de machine learning?
Os principais componentes incluem coleta de dados, pré-processamento de dados, engenharia de features, seleção de modelo, treinamento de modelo, avaliação de modelo, implantação de modelo e monitoramento e manutenção contínuos.
- Quais são os benefícios de usar um pipeline de machine learning?
Pipelines de machine learning proporcionam modularização, eficiência, reprodutibilidade, escalabilidade, colaboração aprimorada e implantação mais fácil de modelos em ambientes de produção.
- Quais são os casos de uso comuns para pipelines de machine learning?
Os casos de uso incluem processamento de linguagem natural (PLN), manutenção preditiva na manufatura, avaliação de risco financeiro e detecção de fraudes, além de diagnósticos em saúde.
- Quais desafios estão associados a pipelines de machine learning?
Os desafios incluem garantir a qualidade dos dados, gerenciar a complexidade do pipeline, integrar com sistemas existentes e controlar custos relacionados a recursos computacionais e infraestrutura.
Comece a Construir Suas Soluções de IA
Agende uma demonstração para descobrir como o FlowHunt pode ajudar você a automatizar e escalar seus fluxos de trabalho de machine learning com facilidade.
Saiba mais
