Interpretabilidade de Modelos
Interpretabilidade de modelos é a capacidade de entender e confiar nas previsões de IA, essencial para transparência, conformidade e mitigação de vieses em setores como saúde e finanças.
Interpretabilidade de Modelos
Interpretabilidade de modelos é entender e confiar nas previsões de IA, sendo fundamental em áreas como saúde e finanças. Envolve interpretabilidade global e local, promovendo confiança, conformidade e mitigação de vieses por meio de métodos intrínsecos e pós-hoc.
Interpretabilidade de modelos refere-se à capacidade de entender, explicar e confiar nas previsões e decisões feitas por modelos de aprendizado de máquina. É um componente crítico no campo da inteligência artificial, especialmente em aplicações que envolvem tomada de decisão, como saúde, finanças e sistemas autônomos. O conceito é central para a ciência de dados, pois faz a ponte entre modelos computacionais complexos e a compreensão humana.
O que é Interpretabilidade de Modelos?
Interpretabilidade de modelos é o grau em que um humano pode prever consistentemente os resultados do modelo e entender a causa de uma previsão. Isso envolve compreender a relação entre as características de entrada e os resultados produzidos pelo modelo, permitindo que as partes interessadas compreendam os motivos por trás de previsões específicas. Essa compreensão é fundamental para construir confiança, garantir conformidade com regulamentos e orientar processos de tomada de decisão.
De acordo com um framework discutido por Lipton (2016) e Doshi-Velez & Kim (2017), interpretabilidade abrange a capacidade de avaliar e obter informações de modelos que o objetivo sozinho não pode transmitir.
Interpretabilidade Global vs. Local
A interpretabilidade de modelos pode ser categorizada em dois tipos principais:
Interpretabilidade Global: Fornece uma compreensão geral de como um modelo opera, oferecendo uma visão do seu processo decisório geral. Envolve entender a estrutura do modelo, seus parâmetros e as relações que ele captura do conjunto de dados. Esse tipo de interpretabilidade é fundamental para avaliar o comportamento do modelo em uma ampla gama de entradas.
Interpretabilidade Local: Foca em explicar previsões individuais, oferecendo insights sobre por que um modelo tomou uma decisão específica para um determinado caso. A interpretabilidade local ajuda a entender o comportamento do modelo em cenários particulares e é essencial para depuração e refinamento de modelos. Métodos como LIME e SHAP são frequentemente usados para alcançar interpretabilidade local ao aproximar a fronteira de decisão do modelo ao redor de um caso específico.
Importância da Interpretabilidade de Modelos
Confiança e Transparência
Modelos interpretáveis são mais propensos a serem confiáveis por usuários e partes interessadas. Transparência em como um modelo chega às suas decisões é fundamental, especialmente em setores como saúde ou finanças, onde as decisões podem ter impactos éticos e legais significativos. A interpretabilidade facilita o entendimento e a depuração, garantindo que os modelos possam ser confiáveis e utilizados em processos críticos de decisão.
Segurança e Conformidade Regulatória
Em domínios de alto risco, como diagnósticos médicos ou direção autônoma, a interpretabilidade é necessária para garantir segurança e atender a padrões regulatórios. Por exemplo, o Regulamento Geral de Proteção de Dados (GDPR) da União Europeia exige que os indivíduos tenham o direito a uma explicação de decisões algorítmicas que os afetem significativamente. A interpretabilidade de modelos ajuda as instituições a cumprir essas regulações, fornecendo explicações claras dos resultados algorítmicos.
Detecção e Mitigação de Vieses
A interpretabilidade é vital para identificar e mitigar vieses em modelos de aprendizado de máquina. Modelos treinados com dados enviesados podem inadvertidamente aprender e propagar vieses sociais. Compreendendo o processo decisório, os profissionais podem identificar características tendenciosas e ajustar os modelos, promovendo justiça e equidade nos sistemas de IA.
Depuração e Aprimoramento de Modelos
Modelos interpretáveis facilitam o processo de depuração ao permitir que cientistas de dados entendam e corrijam erros nas previsões. Esse entendimento pode levar a melhorias e aprimoramentos do modelo, garantindo melhor desempenho e precisão. A interpretabilidade auxilia na descoberta das razões subjacentes para erros do modelo ou comportamentos inesperados, orientando o desenvolvimento futuro.
Métodos para Alcançar Interpretabilidade
Diversas técnicas e abordagens podem ser empregadas para aumentar a interpretabilidade de modelos, divididas em duas categorias principais: métodos intrínsecos e pós-hoc.
Interpretabilidade Intrínseca
Consiste em utilizar modelos que são inerentemente interpretáveis devido à sua simplicidade e transparência. Exemplos incluem:
- Regressão Linear: Oferece insights diretos sobre como as características de entrada afetam as previsões, tornando fácil de entender e analisar.
- Árvores de Decisão: Fornecem uma representação visual e lógica das decisões, facilitando a interpretação e comunicação aos envolvidos.
- Modelos Baseados em Regras: Utilizam um conjunto de regras para tomar decisões, que podem ser analisadas e compreendidas diretamente, oferecendo clareza ao processo decisório.
Interpretabilidade Pós-hoc
Esses métodos são aplicados a modelos complexos após o treinamento para torná-los mais interpretáveis:
- LIME (Local Interpretable Model-agnostic Explanations): Fornece explicações locais ao aproximar as previsões do modelo com modelos interpretáveis em torno do caso de interesse, ajudando a entender previsões específicas.
- SHAP (SHapley Additive exPlanations): Oferece uma medida unificada de importância das características ao considerar a contribuição de cada característica para a previsão, proporcionando insights sobre o processo decisório do modelo.
- Gráficos de Dependência Parcial (PDPs): Visualizam a relação entre uma característica e o resultado previsto, marginalizando sobre outras características, permitindo entender os efeitos das variáveis.
- Mapas de Saliência: Destacam as áreas nos dados de entrada que mais influenciam as previsões, sendo comuns em processamento de imagens para entender o foco do modelo.
Casos de Uso da Interpretabilidade de Modelos
Saúde
Em diagnósticos médicos, a interpretabilidade é crucial para validar previsões de IA e garantir que estejam alinhadas com o conhecimento clínico. Modelos utilizados para diagnosticar doenças ou recomendar tratamentos precisam ser interpretáveis para conquistar a confiança de profissionais e pacientes, facilitando melhores resultados em saúde.
Finanças
Instituições financeiras utilizam aprendizado de máquina para análise de crédito, detecção de fraudes e avaliação de riscos. A interpretabilidade garante conformidade com regulamentações e auxilia na compreensão das decisões financeiras, facilitando a justificativa para partes interessadas e reguladores. Isso é fundamental para manter confiança e transparência nas operações financeiras.
Sistemas Autônomos
Em veículos autônomos e robótica, a interpretabilidade é importante para segurança e confiabilidade. Compreender o processo decisório dos sistemas de IA auxilia na previsão de comportamentos em cenários reais e garante que operem dentro de limites éticos e legais, essenciais para a segurança e confiança pública.
Automação de IA e Chatbots
Em automação de IA e chatbots, a interpretabilidade ajuda no refinamento de modelos conversacionais e garante respostas relevantes e precisas. Auxilia no entendimento da lógica por trás das interações dos chatbots e na melhoria da satisfação do usuário, aprimorando a experiência geral.
Desafios e Limitações
Trade-off entre Interpretabilidade e Precisão
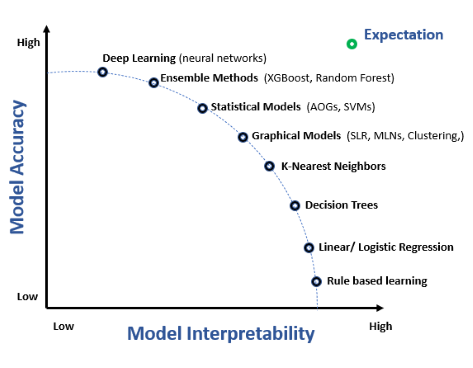
Frequentemente existe um equilíbrio entre interpretabilidade e precisão do modelo. Modelos complexos, como redes neurais profundas, podem oferecer maior precisão, mas são menos interpretáveis. Alcançar o equilíbrio entre ambos é um desafio significativo, exigindo consideração cuidadosa das necessidades da aplicação e requisitos das partes interessadas.
Interpretabilidade Específica do Domínio
O nível de interpretabilidade exigido pode variar significativamente entre diferentes domínios e aplicações. Os modelos precisam ser adaptados às necessidades e requisitos específicos do domínio para fornecer insights significativos e acionáveis. Isso envolve compreender os desafios do domínio e projetar modelos que os abordem de forma eficaz.
Avaliação da Interpretabilidade
Medir a interpretabilidade é desafiador, pois é subjetiva e dependente do contexto. Enquanto alguns modelos podem ser interpretáveis para especialistas, podem não ser compreensíveis para leigos. O desenvolvimento de métricas padronizadas para avaliação da interpretabilidade permanece uma área ativa de pesquisa, essencial para o avanço do campo e para garantir a implantação de modelos interpretáveis.
Pesquisa sobre Interpretabilidade de Modelos
A interpretabilidade de modelos é um foco crítico em aprendizado de máquina, pois permite o entendimento e a confiança em modelos preditivos, especialmente em áreas como medicina de precisão e sistemas automatizados de decisão. Veja alguns estudos fundamentais que exploram esse tema:
Modelo Preditivo Híbrido: Quando um Modelo Interpretável Colabora com um Modelo Caixa-preta
Autores: Tong Wang, Qihang Lin (Publicado em: 10/05/2019)
Este artigo apresenta uma estrutura para criar um Modelo Preditivo Híbrido (HPM) que une as forças de modelos interpretáveis e modelos caixa-preta. O modelo híbrido substitui o modelo caixa-preta em partes dos dados onde alto desempenho não é necessário, aumentando a transparência com mínima perda de precisão. Os autores propõem uma função objetivo que pondera precisão preditiva, interpretabilidade e transparência do modelo. O estudo demonstra a eficácia do modelo híbrido em equilibrar transparência e desempenho preditivo, especialmente em cenários de dados estruturados e de texto. Leia maisInterpretabilidade de Modelos de Aprendizado de Máquina para Medicina de Precisão
Autores: Gajendra Jung Katuwal, Robert Chen (Publicado em: 28/10/2016)
Esta pesquisa destaca a importância da interpretabilidade em modelos de aprendizado de máquina para medicina de precisão. Utiliza o algoritmo Model-Agnostic Explanations para tornar interpretáveis modelos complexos, como florestas aleatórias. O estudo aplicou essa abordagem ao conjunto de dados MIMIC-II, prevendo mortalidade em UTI com 80% de acurácia balanceada e elucidando o impacto individual das características, essencial para decisões médicas. Leia maisAs Definições de Interpretabilidade e o Aprendizado de Modelos Interpretáveis
Autores: Weishen Pan, Changshui Zhang (Publicado em: 29/05/2021)
O artigo propõe uma nova definição matemática de interpretabilidade em modelos de aprendizado de máquina. Define interpretabilidade em termos de sistemas de reconhecimento humano e apresenta uma estrutura para treinar modelos totalmente interpretáveis por humanos. O estudo mostrou que tais modelos não apenas fornecem processos decisórios transparentes, mas também são mais robustos contra ataques adversariais. Leia mais
Perguntas frequentes
- O que é interpretabilidade de modelos em aprendizado de máquina?
Interpretabilidade de modelos é o grau em que um humano pode prever e entender consistentemente os resultados de um modelo, explicando como as características de entrada se relacionam com os resultados e por que um modelo toma decisões específicas.
- Por que a interpretabilidade de modelos é importante?
Interpretabilidade gera confiança, garante conformidade com regulações, auxilia na detecção de vieses e facilita o debug e aprimoramento de modelos de IA, especialmente em domínios sensíveis como saúde e finanças.
- O que são métodos de interpretabilidade intrínseca e pós-hoc?
Métodos intrínsecos utilizam modelos simples e transparentes, como regressão linear ou árvores de decisão, que são interpretáveis por projeto. Métodos pós-hoc, como LIME e SHAP, ajudam a explicar modelos complexos após o treinamento, aproximando ou destacando características importantes.
- Quais são alguns desafios na obtenção de interpretabilidade de modelos?
Os desafios incluem equilibrar precisão com transparência, requisitos específicos do domínio e a natureza subjetiva da mensuração da interpretabilidade, além do desenvolvimento de métricas padronizadas de avaliação.
Pronto para construir sua própria IA?
Chatbots inteligentes e ferramentas de IA em um só lugar. Conecte blocos intuitivos para transformar suas ideias em Fluxos automatizados.