Pipeline de Recuperação
Um pipeline de recuperação permite que chatbots busquem e processem conhecimento externo relevante para respostas precisas, em tempo real e contextuais usando RAG, embeddings e bancos de dados vetoriais.
O que é um Pipeline de Recuperação para Chatbots?
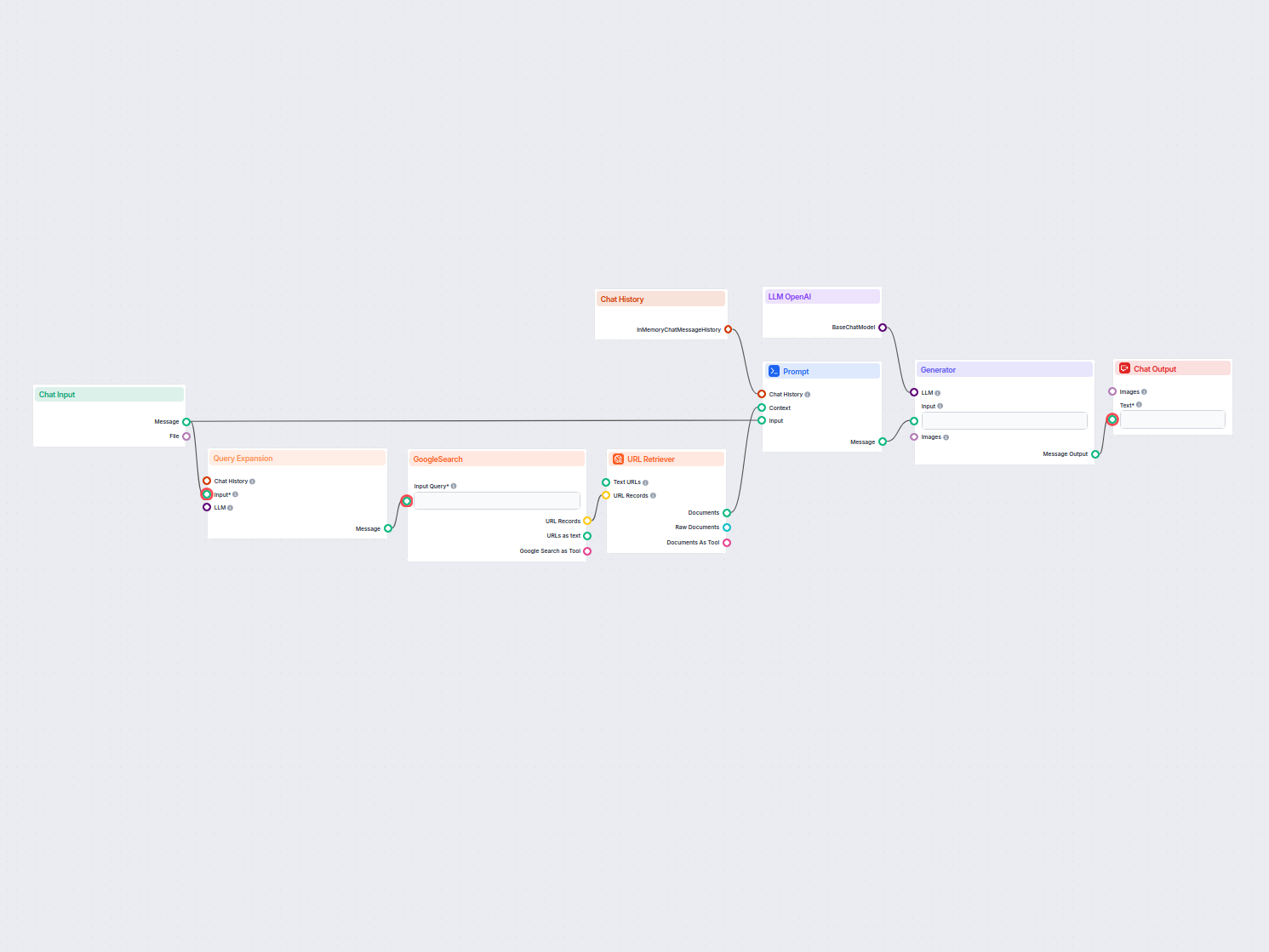
Um pipeline de recuperação para chatbots refere-se à arquitetura técnica e ao processo que permite aos chatbots buscar, processar e recuperar informações relevantes em resposta às perguntas dos usuários. Diferente de sistemas simples de perguntas e respostas que dependem apenas de modelos de linguagem pré-treinados, os pipelines de recuperação incorporam bases de conhecimento externas ou fontes de dados. Isso permite que o chatbot forneça respostas precisas, contextualmente relevantes e atualizadas mesmo quando os dados não estão presentes no próprio modelo de linguagem.
O pipeline de recuperação normalmente consiste em vários componentes, incluindo ingestão de dados, criação de embeddings, armazenamento vetorial, recuperação de contexto e geração de resposta. Sua implementação frequentemente utiliza a Recuperação Aumentada por Geração (RAG), que combina as forças de sistemas de recuperação de dados e Grandes Modelos de Linguagem (LLMs) para geração de respostas.
Como um Pipeline de Recuperação é Utilizado em Chatbots?
Um pipeline de recuperação é usado para aprimorar as capacidades de um chatbot, permitindo que ele:
- Acesse Conhecimento Específico de Domínio
Pode consultar bancos de dados externos, documentos ou APIs para recuperar informações precisas relevantes à pergunta do usuário. - Gere Respostas Contextuais
Ao aumentar os dados recuperados com geração de linguagem natural, o chatbot produz respostas coerentes e personalizadas. - Garanta Informações Atualizadas
Diferente dos modelos de linguagem estáticos, o pipeline permite a recuperação em tempo real de informações de fontes dinâmicas.
Principais Componentes de um Pipeline de Recuperação
Ingestão de Documentos
Coleta e pré-processamento de dados brutos, que podem incluir PDFs, arquivos de texto, bancos de dados ou APIs. Ferramentas como LangChain ou LlamaIndex são frequentemente utilizadas para ingestão de dados eficiente.
Exemplo: Carregar FAQs de atendimento ao cliente ou especificações de produtos no sistema.Pré-processamento de Documentos
Documentos longos são divididos em partes menores e semanticamente significativas. Isso é essencial para encaixar o texto em modelos de embedding que geralmente possuem limites de tokens (ex: 512 tokens).Exemplo de Trecho de Código:
from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50) chunks = text_splitter.split_documents(document_list)Geração de Embeddings
Os dados textuais são convertidos em representações vetoriais de alta dimensão usando modelos de embedding. Esses embeddings codificam numericamente o significado semântico dos dados. Exemplo de Modelo de Embedding:text-embedding-ada-002da OpenAI oue5-large-v2da Hugging Face.Armazenamento Vetorial
Os embeddings são armazenados em bancos de dados vetoriais otimizados para buscas por similaridade. Ferramentas como Milvus, Chroma ou PGVector são comumente usadas. Exemplo: Armazenar descrições de produtos e seus embeddings para recuperação eficiente.Processamento de Consultas
Quando uma pergunta do usuário é recebida, ela é transformada em um vetor de consulta usando o mesmo modelo de embedding. Isso permite a correspondência semântica com os embeddings armazenados.Exemplo de Trecho de Código:
query_vector = embedding_model.encode("Quais são as especificações do Produto X?") retrieved_docs = vector_db.similarity_search(query_vector, k=5)Recuperação de Dados
O sistema recupera os trechos mais relevantes de dados com base nos scores de similaridade (por exemplo, similaridade cosseno). Sistemas de recuperação multimodais podem combinar bancos de dados SQL, grafos de conhecimento e buscas vetoriais para resultados mais robustos.Geração de Resposta
Os dados recuperados são combinados com a pergunta do usuário e enviados para um grande modelo de linguagem (LLM) para gerar uma resposta final em linguagem natural. Esta etapa é frequentemente chamada de geração aumentada.Exemplo de Template de Prompt:
prompt_template = """ Context: {context} Question: {question} Please provide a detailed response using the context above. """Pós-processamento e Validação
Pipelines de recuperação avançados incluem detecção de alucinações, checagem de relevância ou avaliação da resposta para garantir que a saída seja factual e relevante.
Casos de Uso de Pipelines de Recuperação em Chatbots
Suporte ao Cliente
Chatbots podem recuperar manuais de produtos, guias de resolução de problemas ou FAQs para fornecer respostas instantâneas aos clientes.
Exemplo: Um chatbot ajudando um cliente a resetar um roteador ao recuperar a seção relevante do manual do usuário.Gestão do Conhecimento Corporativo
Chatbots internos podem acessar dados específicos da empresa como políticas de RH, documentação de TI ou diretrizes de conformidade.
Exemplo: Funcionários consultando um chatbot interno sobre políticas de licença médica.E-Commerce
Chatbots auxiliam usuários recuperando detalhes de produtos, avaliações ou disponibilidade em estoque.
Exemplo: “Quais são os principais recursos do Produto Y?”Saúde
Chatbots recuperam literatura médica, diretrizes ou dados de pacientes para ajudar profissionais de saúde ou pacientes.
Exemplo: Um chatbot recuperando alertas de interação medicamentosa de um banco de dados farmacêutico.Educação e Pesquisa
Chatbots acadêmicos usam pipelines RAG para buscar artigos científicos, responder perguntas ou resumir descobertas de pesquisas.
Exemplo: “Você pode resumir as descobertas deste estudo de 2023 sobre mudanças climáticas?”Jurídico e Conformidade
Chatbots recuperam documentos legais, jurisprudências ou exigências de conformidade para auxiliar profissionais do direito.
Exemplo: “Qual é a última atualização sobre as regulamentações da GDPR?”
Exemplos de Implementações de Pipeline de Recuperação
Exemplo 1: Q&A Baseado em PDF
Um chatbot criado para responder perguntas a partir do relatório financeiro anual de uma empresa em formato PDF.
Exemplo 2: Recuperação Híbrida
Um chatbot que combina busca SQL, busca vetorial e grafos de conhecimento para responder à pergunta de um funcionário.
Benefícios do Uso de um Pipeline de Recuperação
- Precisão
Reduz alucinações ao fundamentar respostas em dados factuais recuperados. - Relevância Contextual
Personaliza respostas com base em dados específicos do domínio. - Atualizações em Tempo Real
Mantém a base de conhecimento do chatbot atualizada com fontes dinâmicas de dados. - Eficiência de Custos
Diminui a necessidade de fine-tuning caro de LLMs ao complementar com dados externos. - Transparência
Fornece fontes rastreáveis e verificáveis para as respostas do chatbot.
Desafios e Considerações
- Latência
A recuperação em tempo real pode introduzir atrasos, especialmente em pipelines com várias etapas. - Custo
Mais chamadas de API para LLMs ou bancos de dados vetoriais podem resultar em custos operacionais mais altos. - Privacidade de Dados
Dados sensíveis devem ser tratados de forma segura, especialmente em sistemas RAG auto-hospedados. - Escalabilidade
Pipelines em larga escala exigem design eficiente para evitar gargalos na recuperação ou armazenamento de dados.
Tendências Futuras
- Pipelines RAG Agentes
Agentes autônomos realizando raciocínio e recuperação em múltiplas etapas. - Modelos de Embedding Fine-Tuned
Embeddings específicos de domínio para buscas semânticas aprimoradas. - Integração com Dados Multimodais
Expansão da recuperação para imagens, áudio e vídeo além de texto.
Ao utilizar pipelines de recuperação, chatbots deixam de ser limitados pelas restrições de dados de treinamento estáticos, tornando possível fornecer interações dinâmicas, precisas e ricas em contexto.
Pesquisa sobre Pipelines de Recuperação para Chatbots
Pipelines de recuperação desempenham um papel fundamental em sistemas modernos de chatbots, permitindo interações inteligentes e contextuais.
“Lingke: A Fine-grained Multi-turn Chatbot for Customer Service” de Pengfei Zhu et al. (2018)
Apresenta o Lingke, um chatbot que integra recuperação de informações para lidar com conversas de múltiplas interações. Ele utiliza processamento detalhado em pipeline para extrair respostas de documentos não estruturados e emprega correspondência atenta contexto-resposta para interações sequenciais, melhorando significativamente a capacidade do chatbot de lidar com perguntas complexas dos usuários.
Leia o artigo aqui.“FACTS About Building Retrieval Augmented Generation-based Chatbots” de Rama Akkiraju et al. (2024)
Explora os desafios e metodologias no desenvolvimento de chatbots corporativos usando pipelines de Recuperação Aumentada por Geração (RAG) e Grandes Modelos de Linguagem (LLMs). Os autores propõem o framework FACTS, enfatizando Freshness, Architectures, Cost, Testing e Security na engenharia de pipelines RAG. As descobertas empíricas destacam os trade-offs entre precisão e latência ao escalar LLMs, oferecendo insights valiosos para a construção de chatbots seguros e de alta performance. Leia o artigo aqui.“From Questions to Insightful Answers: Building an Informed Chatbot for University Resources” de Subash Neupane et al. (2024)
Apresenta o BARKPLUG V.2, um sistema de chatbot projetado para ambientes universitários. Utilizando pipelines RAG, o sistema fornece respostas precisas e específicas do domínio aos usuários sobre recursos do campus, melhorando o acesso à informação. O estudo avalia a eficácia do chatbot usando frameworks como RAG Assessment (RAGAS) e demonstra sua usabilidade em ambientes acadêmicos. Leia o artigo aqui.
Perguntas frequentes
- O que é um pipeline de recuperação em chatbots?
Um pipeline de recuperação é uma arquitetura técnica que permite aos chatbots buscar, processar e recuperar informações relevantes de fontes externas em resposta a perguntas dos usuários. Ele combina ingestão de dados, embedding, armazenamento vetorial e geração de respostas por LLM para respostas dinâmicas e contextuais.
- Como a Recuperação Aumentada por Geração (RAG) melhora as respostas do chatbot?
RAG combina as forças de sistemas de recuperação de dados e grandes modelos de linguagem (LLMs), permitindo que chatbots fundamentem suas respostas em dados externos factuais e atualizados, reduzindo alucinações e aumentando a precisão.
- Quais são os componentes típicos de um pipeline de recuperação?
Os principais componentes incluem ingestão de documentos, pré-processamento, geração de embedding, armazenamento vetorial, processamento de consultas, recuperação de dados, geração de respostas e validação pós-processamento.
- Quais são os casos de uso comuns de pipelines de recuperação em chatbots?
Os casos de uso incluem suporte ao cliente, gestão do conhecimento corporativo, informações de produtos em e-commerce, orientação em saúde, educação e pesquisa e assistência à conformidade legal.
- Quais desafios devo considerar ao construir um pipeline de recuperação?
Os desafios incluem latência na recuperação em tempo real, custos operacionais, preocupações com privacidade de dados e requisitos de escalabilidade para lidar com grandes volumes de dados.
Comece a Construir Chatbots com IA usando Pipelines de Recuperação
Desbloqueie o poder da Recuperação Aumentada por Geração (RAG) e integração de dados externos para fornecer respostas inteligentes e precisas em chatbots. Experimente a plataforma sem código da FlowHunt hoje mesmo.
Saiba mais