
Recuperador de Documentos
O Recuperador de Documentos da FlowHunt melhora a precisão da IA ao conectar modelos generativos aos seus próprios documentos e URLs atualizados, garantindo res...
4 min de leitura
AI
Document Retrieval
+3
Aprenda a configurar os parâmetros ‘A partir do H1 se existir’, ‘Carregar do marcador’ e ‘Ignorar último cabeçalho’.
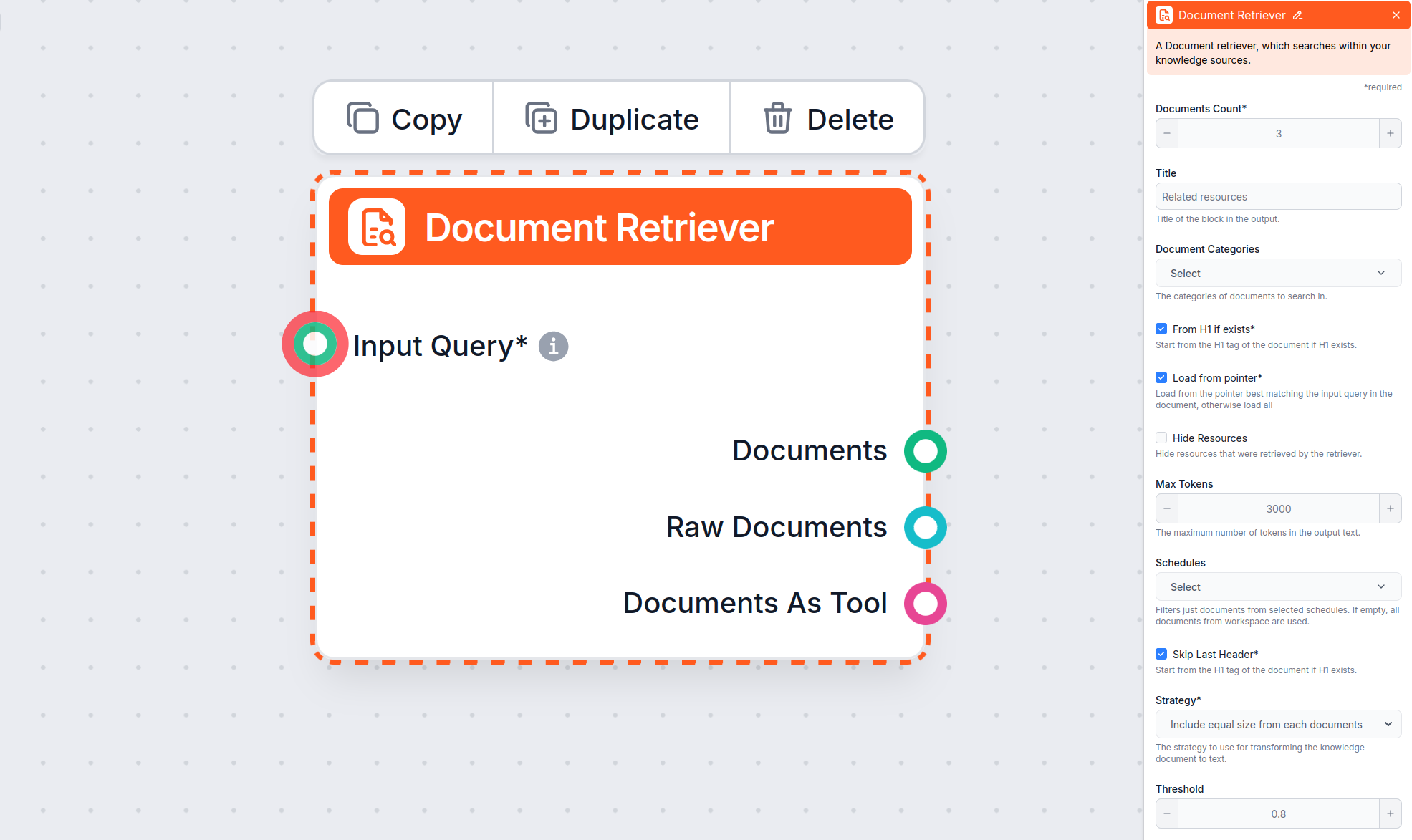
O componente Document Retriever permite que o chatbot recupere conhecimento das fontes que você especificou nos Documentos e Agendas. O papel deste componente é controlar a extração, e vários parâmetros afetam como o componente recupera informações desses documentos.
A opção A partir do H1 se existir instrui o retriever a começar a extrair o conteúdo a partir do cabeçalho H1 encontrado (geralmente o título principal do artigo).
O que acontece?
Exemplo de uso:
Você deseja recuperar apenas o guia real, sem qualquer navegação do site ou cabeçalho da página que exista em seu site.
Observação:
A partir do H1 se existir vem ativado por padrão no componente Document Retriever.
A opção Carregar do marcador oferece mais precisão ao permitir que o Document Retriever carregue apenas dados a partir de um marcador em um artigo possivelmente longo.
O que acontece?
O que é um “marcador”?
Um marcador normalmente é uma string única ou cabeçalho presente no documento (por exemplo, um H2 ou uma frase ou título de seção específico).
Exemplo de uso:
Você deseja pular seções introdutórias e recuperar informações de uma seção específica de um artigo ou documento longo (por exemplo, a partir de “Etapa 4: Adicionar um botão de chat ao vivo” em um guia de configuração).
A opção Ignorar último cabeçalho é útil para ignorar o último cabeçalho do documento, que frequentemente é repetido ou usado para navegação ou propósitos de rodapé.
O que acontece?
Exemplo de uso:
Você deseja evitar que o Document Retriever carregue um cabeçalho de navegação de rodapé (como “Outros artigos” no final de uma página de ajuda), garantindo que apenas o conteúdo principal seja processado.
Observação:
Ignorar último cabeçalho pode ajudar em documentos que geram rodapés ou elementos de navegação repetitivos automaticamente. No entanto, caso você não tenha tais seções, usar esse parâmetro pode fazer com que parte do artigo com informações válidas não seja recuperada. Portanto, recomenda-se deixar esta opção desmarcada até que haja um motivo válido para ativá-la.
O parâmetro Máx. de tokens permite controlar o número máximo de tokens (palavras e sinais de pontuação, conforme contado pelo modelo de IA utilizado) que o Document Retriever irá gerar do texto extraído.
O que acontece?
Valor padrão:
O valor padrão normalmente é 3.000 tokens, mas pode ser ajustado conforme necessário.
Exemplo de uso:
Se você está processando documentos extensos, definir um valor menor para Máx. de tokens ajuda a manter as respostas concisas. Contudo, para melhores resultados, considere ativar o parâmetro “Carregar do marcador”. Isso garante que o texto extraído comece na seção mais relevante do documento, em vez do início, permitindo obter uma informação mais focada e gerenciável dentro do limite de tokens especificado. Essa combinação é especialmente útil quando deseja saídas concisas e contextualmente relevantes de fontes grandes.
Observação:
Se perceber que informações estão sendo cortadas, tente aumentar o valor de Máx. de tokens. Por outro lado, se quiser respostas mais curtas e objetivas, reduza esse parâmetro.
Quando o Document Retriever encontra vários documentos relevantes, o parâmetro Estratégia determina como eles são mesclados em uma única saída de texto para seu chatbot, levando em consideração o limite de “Máx. de tokens”.
Duas opções de estratégia:
Incluir tamanho igual de cada documento:
O limite de tokens é dividido igualmente. Por exemplo, com três documentos e um limite de 3.000 tokens, cada um pode ter até 1.000 tokens. Isso garante que todas as fontes contribuam de forma equilibrada, útil quando você deseja uma resposta balanceada que utilize múltiplos documentos.
Concatenar documentos, preencher a partir do primeiro até o limite de tokens:
Os documentos são adicionados em ordem de relevância até que o limite de tokens seja atingido. O documento mais relevante preenche o espaço primeiro; se sobrar espaço, documentos menos relevantes são adicionados em ordem. Se o primeiro documento for extenso, pode usar todo o limite sozinho.
Como escolher?
Observação:
Essas estratégias afetam apenas como o texto é construído a partir dos documentos recuperados antes de ser passado para o próximo passo (como geração por IA). Elas não alteram quais documentos são recuperados—apenas como seu conteúdo é mesclado e cortado para caber no limite de Máx. de tokens.
Embora este artigo foque na configuração dos parâmetros ‘A partir do H1 se existir’, ‘Carregar do marcador’, ‘Ignorar último cabeçalho’ e ‘Máx. de tokens’, o Document Retriever também oferece parâmetros adicionais que ajudam a controlar como os documentos são selecionados e recuperados:
Esta configuração limita o número de documentos que o fluxo deve recuperar, garantindo que os resultados permaneçam relevantes e as respostas sejam geradas rapidamente.
Esta configuração opcional permite limitar a recuperação a uma ou mais categorias que você criou na seção Documentos das Fontes de Conhecimento.
Permite incluir ou ocultar uma seção separada, antes da resposta do chatbot, com uma lista de recursos que foram recuperados pelo retriever. Para integração com LiveAgent, ela deve estar marcada, pois essa seção não é suportada e não será exibida corretamente no widget do chatbot do LiveAgent.
Permite restringir a recuperação a uma ou mais Agendas que você especificou para rastrear ou atualizar conteúdo em Fontes de Conhecimento.
Controla o quão próximos os documentos recuperados devem estar da consulta de entrada, usando uma pontuação de relevância (de 0 a 1). Por exemplo, recomenda-se um limite de 0,7–0,8 para respostas altamente relevantes. Limites mais altos fornecem correspondências mais precisas, enquanto limites mais baixos podem incluir documentos menos relevantes.
Exemplo:
Se você definir um limite de 0,6 e tiver quatro artigos com pontuações de relevância de 0,8, 0,65, 0,5 e 0,9, apenas os que estiverem acima de 0,6 (ou seja, 0,8, 0,65 e 0,9) serão usados para extração.
Se a resposta fornecida pelo chatbot não contiver informações que você tem certeza que ele possui em seus documentos ou agendas, tente verificar o histórico da conversa com a opção “Verbose” para ver logs detalhados sobre se o Document Retriever foi utilizado e quais documentos foram recuperados. Se necessário, ajuste suas configurações e prompt com base nesses logs.
O Recuperador de Documentos da FlowHunt melhora a precisão da IA ao conectar modelos generativos aos seus próprios documentos e URLs atualizados, garantindo res...
Seu chatbot pode acessar e utilizar instantaneamente documentos, páginas HTML e até vídeos do YouTube para adaptar o seu contexto único. Perfeito para adicionar...
Integre seus fluxos de trabalho com o Google Docs usando o componente Google Docs Retriever—busque o conteúdo de documentos de forma transparente para usar em a...