
Servidor MCP do Databricks
Conecte seus agentes de IA ao Databricks para automação de SQL, monitoramento de jobs e gestão de fluxos de trabalho usando o Servidor MCP do Databricks no FlowHunt.

O que faz o Servidor MCP “Databricks”?
O Servidor MCP (Model Context Protocol) do Databricks é uma ferramenta especializada que conecta assistentes de IA à plataforma Databricks, permitindo interação perfeita com os recursos do Databricks por meio de interfaces de linguagem natural. Este servidor atua como ponte entre grandes modelos de linguagem (LLMs) e as APIs do Databricks, permitindo que os LLMs executem consultas SQL, listem jobs, recuperem status de jobs e obtenham informações detalhadas de jobs. Ao expor essas capacidades via protocolo MCP, o servidor MCP do Databricks capacita desenvolvedores e agentes de IA a automatizar fluxos de trabalho de dados, gerenciar jobs no Databricks e otimizar operações de banco de dados, aumentando assim a produtividade em ambientes de desenvolvimento orientados a dados.
Lista de Prompts
Nenhum modelo de prompt está descrito no repositório.
Lista de Recursos
Nenhum recurso explícito está listado no repositório.
Lista de Ferramentas
- run_sql_query(sql: str)
Executa consultas SQL no warehouse Databricks SQL. - list_jobs()
Lista todos os jobs do Databricks no workspace. - get_job_status(job_id: int)
Recupera o status de um job específico do Databricks pelo seu ID. - get_job_details(job_id: int)
Obtém informações detalhadas de um job específico do Databricks.
Casos de Uso deste Servidor MCP
- Automação de Consultas ao Banco de Dados
Permite que LLMs e usuários executem consultas SQL em warehouses do Databricks diretamente de interfaces conversacionais, otimizando fluxos de análise de dados. - Gerenciamento de Jobs
Lista e monitora jobs do Databricks, ajudando os usuários a acompanhar tarefas em andamento ou agendadas em seu workspace. - Acompanhamento de Status de Jobs
Recupera rapidamente o status de jobs específicos do Databricks, permitindo monitoramento e solução de problemas eficiente. - Inspeção Detalhada de Jobs
Acessa informações aprofundadas sobre jobs do Databricks, facilitando o debug e a otimização de pipelines ETL ou jobs em lote.
Como configurar
Windsurf
- Certifique-se de que o Python 3.7+ está instalado e de que as credenciais do Databricks estão disponíveis.
- Clone o repositório e instale os requisitos com
pip install -r requirements.txt. - Crie um arquivo
.envcom suas credenciais do Databricks. - Adicione o Servidor MCP do Databricks à sua configuração do Windsurf:
{ "mcpServers": { "databricks": { "command": "python", "args": ["main.py"] } } } - Salve a configuração e reinicie o Windsurf. Verifique a configuração executando uma consulta de teste.
Exemplo de proteção de chaves de API:
{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"],
"env": {
"DATABRICKS_HOST": "${DATABRICKS_HOST}",
"DATABRICKS_TOKEN": "${DATABRICKS_TOKEN}",
"DATABRICKS_HTTP_PATH": "${DATABRICKS_HTTP_PATH}"
}
}
}
}
Claude
- Instale o Python 3.7+ e clone o repositório.
- Configure o arquivo
.envcom as credenciais do Databricks. - Configure a interface MCP do Claude:
{ "mcpServers": { "databricks": { "command": "python", "args": ["main.py"] } } } - Reinicie o Claude e valide a conexão.
Cursor
- Clone o repositório e configure o ambiente Python.
- Instale as dependências e crie o
.envcom as credenciais. - Adicione o servidor à configuração do Cursor:
{ "mcpServers": { "databricks": { "command": "python", "args": ["main.py"] } } } - Salve a configuração e teste a conexão.
Cline
- Prepare o Python e as credenciais como acima.
- Clone o repositório, instale os requisitos e configure o
.env. - Adicione a entrada do servidor MCP à configuração do Cline:
{ "mcpServers": { "databricks": { "command": "python", "args": ["main.py"] } } } - Salve, reinicie o Cline e verifique se o Servidor MCP está operacional.
Nota: Sempre proteja suas chaves e segredos de API utilizando variáveis de ambiente, conforme mostrado nos exemplos de configuração acima.
Como usar este MCP em fluxos
Usando MCP no FlowHunt
Para integrar servidores MCP ao seu fluxo no FlowHunt, comece adicionando o componente MCP ao seu fluxo e conectando-o ao seu agente de IA:
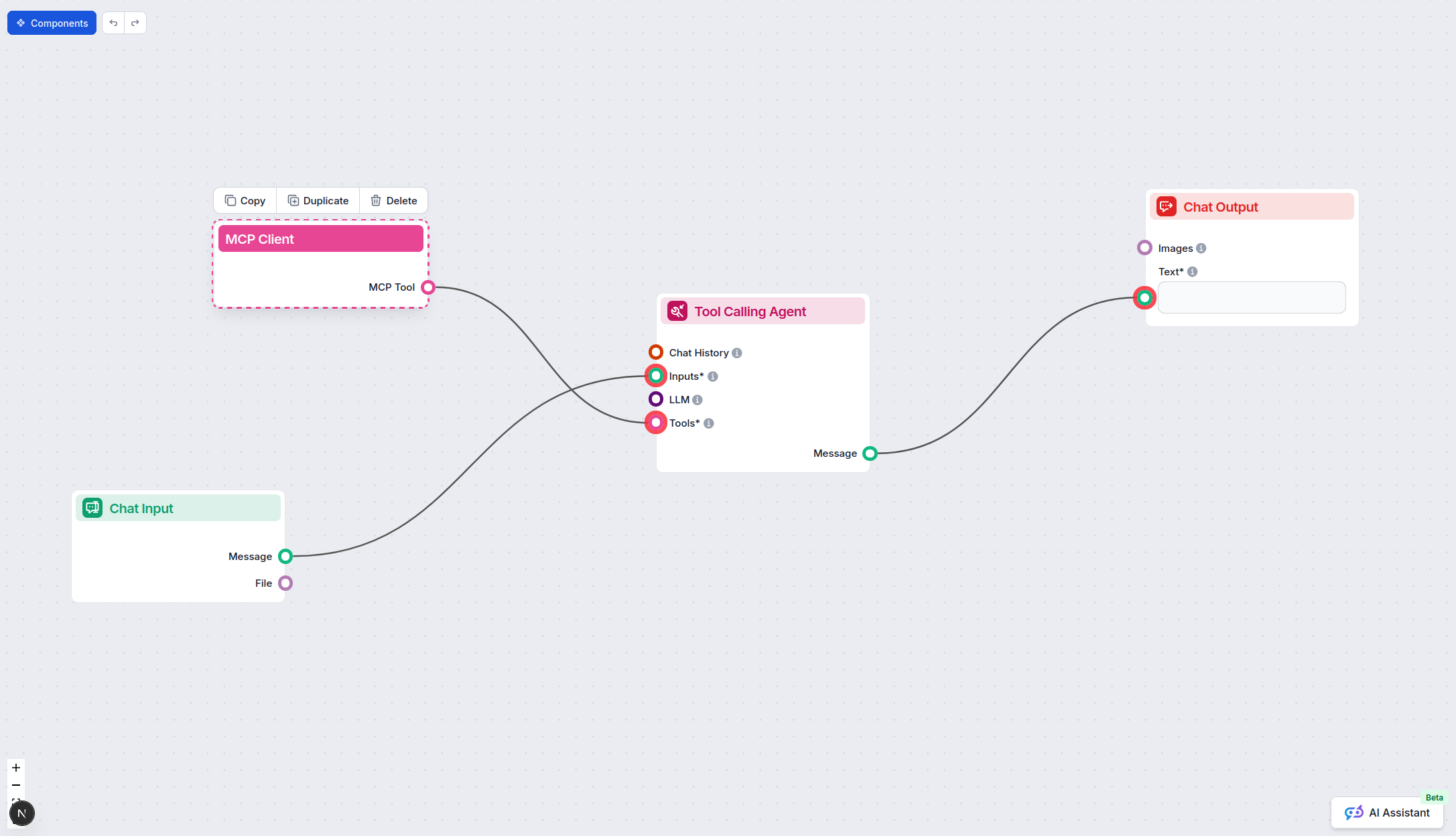
Clique no componente MCP para abrir o painel de configuração. Na seção de configuração do sistema MCP, insira os detalhes do seu servidor MCP usando este formato JSON:
{
"databricks": {
"transport": "streamable_http",
"url": "https://seumcpserver.exemplo/caminhoparamcp/url"
}
}
Uma vez configurado, o agente de IA já pode utilizar este MCP como ferramenta, com acesso a todas as suas funções e capacidades. Lembre-se de substituir “databricks” pelo nome real do seu servidor MCP e trocar a URL pela URL do seu próprio servidor MCP.
Visão Geral
| Seção | Disponibilidade | Detalhes/Notas |
|---|---|---|
| Visão Geral | ✅ | |
| Lista de Prompts | ⛔ | Nenhum modelo de prompt especificado no repositório |
| Lista de Recursos | ⛔ | Nenhum recurso explícito definido |
| Lista de Ferramentas | ✅ | 4 ferramentas: run_sql_query, list_jobs, get_job_status, get_job_details |
| Proteção de Chaves de API | ✅ | Via variáveis de ambiente no .env e config JSON |
| Suporte a Sampling (menos relevante na avaliação) | ⛔ | Não mencionado |
| Suporte Roots | ⛔ | Não mencionado |
Com base na disponibilidade dos recursos principais (ferramentas, orientações de configuração e segurança, mas sem recursos ou modelos de prompt), o Servidor MCP do Databricks é eficaz para integração com a API do Databricks, mas carece de algumas primitivas MCP avançadas. Eu avaliaria este servidor MCP com 6 de 10 em completude e utilidade no contexto do ecossistema MCP.
Pontuação MCP
| Possui LICENSE | ⛔ (não encontrado) |
|---|---|
| Possui ao menos uma ferramenta | ✅ |
| Número de Forks | 13 |
| Número de Stars | 33 |
Perguntas frequentes
- O que é o Servidor MCP do Databricks?
O Servidor MCP do Databricks é uma ponte entre assistentes de IA e o Databricks, expondo capacidades como execução de SQL e gerenciamento de jobs via protocolo MCP para fluxos de trabalho automatizados.
- Quais operações são suportadas por este Servidor MCP?
Ele suporta execução de consultas SQL, listagem de todos os jobs, recuperação de status de jobs e obtenção de informações detalhadas sobre jobs específicos do Databricks.
- Como armazenar minhas credenciais do Databricks de forma segura?
Sempre utilize variáveis de ambiente, por exemplo colocando-as em um arquivo `.env` ou configurando-as na sua configuração do servidor MCP, ao invés de codificar informações sensíveis diretamente.
- Posso usar este servidor em fluxos do FlowHunt?
Sim, basta adicionar o componente MCP ao seu fluxo, configurá-lo com os detalhes do seu servidor MCP do Databricks, e seus agentes de IA poderão acessar todas as funções suportadas do Databricks.
- Qual é a pontuação geral de utilidade deste Servidor MCP?
Com base nas ferramentas disponíveis, orientações de configuração e suporte à segurança, mas sem recursos e modelos de prompt, este Servidor MCP recebe nota 6 de 10 em completude no ecossistema MCP.
Potencialize seus fluxos de trabalho no Databricks
Automatize consultas SQL, monitore jobs e gerencie recursos Databricks diretamente de interfaces conversacionais de IA. Integre o Servidor MCP do Databricks aos seus fluxos FlowHunt para produtividade de outro nível.
Saiba mais

