
Servidor Scrapling Fetch MCP
O Scrapling Fetch MCP Server permite que seus agentes de IA busquem e extraiam conteúdo web protegido, possibilitando assistência rica em contexto e fluxos de trabalho automatizados de documentação mesmo em sites com proteção contra bots.

O que faz o Servidor “Scrapling Fetch” MCP?
O Scrapling Fetch MCP Server é um servidor especializado do Model Context Protocol (MCP) projetado para ajudar assistentes de IA a acessarem conteúdo de texto de sites que implementam proteção contra bots e medidas anti-automação. Utilizando a ferramenta Scrapling, ele faz a ponte entre o que os usuários veem em seus navegadores e o que agentes de IA podem recuperar, tornando possível buscar HTML ou markdown de sites que normalmente bloqueariam raspadores automatizados. O Scrapling Fetch MCP é otimizado para recuperação de baixo volume de documentação e materiais de referência, focando especificamente em texto e HTML, em vez de scraping geral de sites. Isso o torna um recurso valioso para fluxos de trabalho de desenvolvimento que exigem acesso a documentação protegida online ou enriquecimento de contexto, respeitando os limites e o uso pretendido dos sites.
Lista de Prompts
Nenhum template de prompt explícito está documentado no repositório.
Lista de Recursos
Nenhum recurso MCP explícito está documentado no repositório.
Lista de Ferramentas
- s-fetch-page: Recupera páginas web completas, com suporte à paginação para permitir a busca incremental de grandes documentos.
- s-fetch-pattern: Extrai conteúdo específico de páginas web, encontrando padrões regex fornecidos pelo usuário, junto com contexto configurável ao redor.
Casos de Uso deste Servidor MCP
- Acessando Documentação Protegida por Bots: Desenvolvedores podem recuperar documentação ou material de referência de sites que normalmente bloqueiam ferramentas automatizadas, permitindo que assistentes de IA respondam perguntas usando fontes protegidas e atualizadas.
- Extraindo Informações Específicas: Utilize expressões regulares para extrair dados direcionados (como chaves de API, trechos de configuração ou referências) de grandes páginas de documentação, reduzindo ruídos e focando no contexto relevante.
- Resumindo Conteúdo Web: Busque páginas web inteiras e resuma seus conteúdos, facilitando para os usuários a assimilação de documentação extensa ou complexa.
- Assistência Contextual em IDEs: Integre o servidor com ambientes de desenvolvimento, permitindo que ferramentas de IA busquem e forneçam assistência sensível ao contexto usando recursos online protegidos.
- Recuperação Incremental de Páginas: Manipule grandes documentos paginando as requisições, garantindo que até referências extensas possam ser processadas sem esgotar recursos.
Como configurar
Windsurf
Nenhuma instrução específica para Windsurf está documentada no repositório.
Claude
- Certifique-se dos pré-requisitos: Python 3.10+ e o gerenciador de pacotes uv instalados.
- Instale as dependências:
uv tool install scrapling scrapling install uv tool install scrapling-fetch-mcp - Localize o arquivo de configuração do seu cliente Claude.
- Adicione o servidor Scrapling Fetch MCP:
{ "mcpServers": { "Cyber-Chitta": { "command": "uvx", "args": ["scrapling-fetch-mcp"] } } } - Salve e reinicie o cliente Claude para aplicar a configuração.
Segurança de Chaves de API
Não há documentação explícita sobre uso de chaves de API ou configuração de variáveis de ambiente.
Cursor
Nenhuma instrução específica para Cursor está documentada no repositório.
Cline
Nenhuma instrução específica para Cline está documentada no repositório.
Como usar este MCP dentro de fluxos
Usando MCP no FlowHunt
Para integrar servidores MCP ao seu fluxo no FlowHunt, comece adicionando o componente MCP ao seu fluxo e conectando-o ao seu agente de IA:
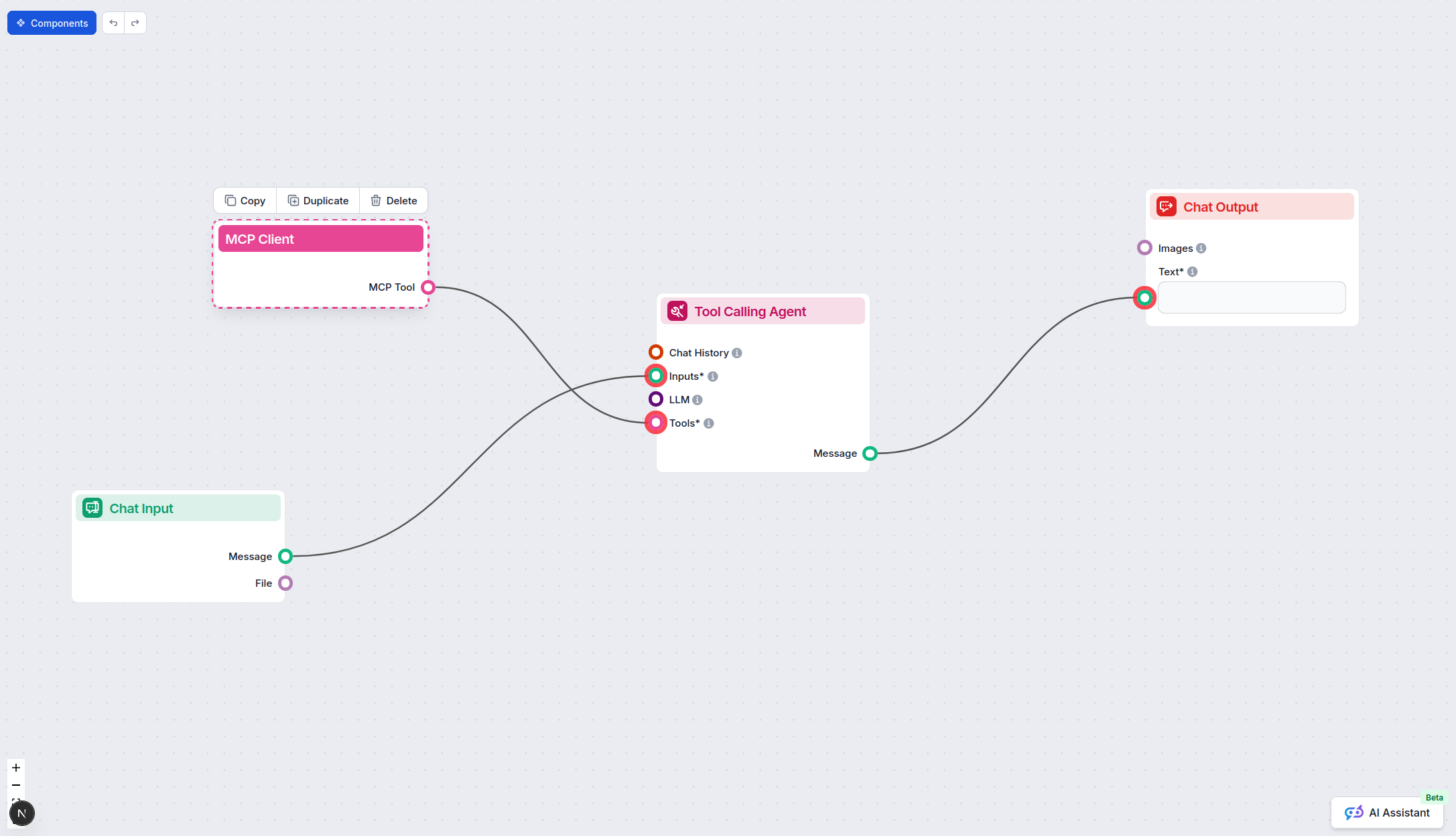
Clique no componente MCP para abrir o painel de configuração. Na seção de configuração do sistema MCP, insira os detalhes do seu servidor MCP usando este formato JSON:
{
"scrapling-fetch": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Após configurado, o agente de IA poderá usar este MCP como uma ferramenta com acesso a todas as suas funções e capacidades. Lembre-se de trocar “scrapling-fetch” pelo nome real do seu servidor MCP e substituir a URL pela URL do seu próprio servidor MCP.
Visão Geral
| Seção | Disponível | Detalhes/Notas |
|---|---|---|
| Visão Geral | ✅ | Visão geral clara no README |
| Lista de Prompts | ⛔ | Nenhum template de prompt documentado |
| Lista de Recursos | ⛔ | Nenhuma definição de recurso MCP documentada |
| Lista de Ferramentas | ✅ | s-fetch-page, s-fetch-pattern |
| Segurança de Chaves de API | ⛔ | Sem detalhes sobre chaves de API ou configuração de variáveis de ambiente |
| Suporte a Amostragem (menos relevante) | ⛔ | Não mencionado |
| Suporte a Roots | ⛔ | Não mencionado |
Entre as duas tabelas, o Scrapling Fetch MCP Server se destaca por fornecer ferramentas claras e úteis para busca web protegida, mas carece de prompts padronizados, declaração de recursos e documentação avançada de segurança/variáveis de ambiente. Com base nos recursos e documentação, avaliamos este MCP com uma nota 6/10 em completude e utilidade geral.
Pontuação MCP
| Possui uma LICENSE | ✅ (Apache-2.0) |
|---|---|
| Possui ao menos uma ferramenta | ✅ |
| Número de Forks | 5 |
| Número de Stars | 31 |
Perguntas frequentes
- O que o Scrapling Fetch MCP Server faz?
Ele permite que agentes de IA e chatbots acessem e extraiam conteúdo em texto ou HTML de sites com proteção contra bots, tornando possível buscar documentação ou material de referência que, de outra forma, seria inacessível para ferramentas automatizadas.
- Quais ferramentas estão disponíveis com o Scrapling Fetch MCP?
Duas ferramentas principais: s-fetch-page (busca páginas web completas, com suporte à paginação para grandes documentos) e s-fetch-pattern (extrai conteúdo que corresponde a padrões regex fornecidos pelo usuário, com contexto configurável).
- Quais são os casos de uso típicos?
Os casos de uso incluem acessar documentação protegida por bots, extrair informações específicas via regex, resumir conteúdo da web, assistência contextual em IDEs e recuperação incremental de grandes documentos.
- Como configuro o Scrapling Fetch MCP no FlowHunt?
Adicione o componente MCP ao seu fluxo, abra o painel de configuração e insira os detalhes do seu servidor em formato JSON na configuração do sistema MCP. Certifique-se de usar o nome e a URL corretos do servidor para sua implantação.
- São necessárias chaves de API ou etapas adicionais de segurança?
A documentação atual não especifica a necessidade de chaves de API ou configuração de variáveis de ambiente para o Scrapling Fetch MCP.
- Qual licença o Scrapling Fetch MCP utiliza?
Ele é lançado sob a licença Apache-2.0, sendo open source e adequado para integração em projetos pessoais e comerciais.
Experimente o Scrapling Fetch MCP Server com o FlowHunt
Integre o Scrapling Fetch MCP Server para potencializar seus fluxos de trabalho de IA com acesso a conteúdo protegido de sites e capacidades aprimoradas de automação web.
Saiba mais

