
Servidor MCP da Wikidata
Conecte seu assistente de IA ao conhecimento estruturado da Wikidata com a integração do Servidor MCP da Wikidata do FlowHunt—habilitando busca semântica, extração de metadados e consultas SPARQL de forma integrada.

O que faz o “Servidor MCP da Wikidata”?
O Servidor MCP da Wikidata é uma implementação de servidor do Model Context Protocol (MCP), projetado para interfacear diretamente com a API da Wikidata. Ele fornece uma ponte entre assistentes de IA e o vasto conhecimento estruturado da Wikidata, permitindo que desenvolvedores e agentes de IA busquem de forma integrada identificadores de entidades e propriedades, extraiam metadados (como rótulos e descrições) e executem consultas SPARQL. Ao expor essas capacidades como ferramentas MCP, o servidor possibilita tarefas como busca semântica, extração de conhecimento e enriquecimento contextual em fluxos de desenvolvimento onde dados estruturados externos são necessários. Isso potencializa aplicações baseadas em IA ao permitir que recuperem, consultem e raciocinem sobre informações atualizadas da Wikidata.
Lista de Prompts
Nenhum template de prompt é mencionado no repositório ou documentação.
Lista de Recursos
Nenhum recurso MCP explícito é descrito no repositório ou documentação.
Lista de Ferramentas
- search_entity(query: str)
Busca um ID de entidade da Wikidata pela consulta fornecida. - search_property(query: str)
Busca um ID de propriedade da Wikidata pela consulta fornecida. - get_properties(entity_id: str)
Obtém as propriedades associadas a um determinado ID de entidade da Wikidata. - execute_sparql(sparql_query: str)
Executa uma consulta SPARQL na Wikidata. - get_metadata(entity_id: str, language: str = “en”)
Recupera o rótulo e a descrição em inglês para um dado ID de entidade da Wikidata.
Casos de Uso deste Servidor MCP
- Recuperação Semântica de Dados
Use assistentes de IA para buscar entidades ou propriedades na Wikidata, fornecendo aos usuários IDs precisos para manipulação ou exploração adicional de dados. - Extração Automatizada de Metadados
Extraia automaticamente rótulos e descrições de entidades da Wikidata, enriquecendo aplicações ou projetos orientados a dados com informações contextuais. - Execução Programática de Consultas SPARQL
Permita que agentes baseados em LLM formulem e executem consultas SPARQL, tornando possível responder perguntas complexas ou obter conhecimento estruturado dinamicamente. - Exploração de Grafo de Conhecimento
Permita que desenvolvedores explorem relações entre entidades e propriedades na Wikidata, apoiando pesquisas, análises de dados e fluxos de trabalho de dados ligados. - Recomendações Assistidas por IA
Construa agentes de IA que recomendam itens (por exemplo, filmes de determinado diretor) combinando busca de entidades, recuperação de propriedades e execução de SPARQL.
Como configurar
Windsurf
- Certifique-se de que o Node.js está instalado.
- Localize o arquivo de configuração do Windsurf.
- Adicione o Servidor MCP da Wikidata à configuração
mcpServersusando um trecho JSON como abaixo. - Salve a configuração e reinicie o Windsurf.
- Verifique se o servidor aparece em suas integrações MCP.
"mcpServers": {
"wikidata-mcp": {
"command": "npx",
"args": ["@zzaebok/mcp-wikidata@latest"]
}
}
Protegendo chaves de API (se necessário):
{
"wikidata-mcp": {
"env": {
"WIKIDATA_API_KEY": "sua-chave-api"
},
"inputs": {
"some_input": "value"
}
}
}
Claude
- Instale o Node.js se ainda não estiver instalado.
- Abra o arquivo de configuração do Claude.
- Insira a seguinte configuração para o Servidor MCP da Wikidata.
- Salve e reinicie o Claude Desktop.
- Confirme que o servidor está acessível.
"mcpServers": {
"wikidata-mcp": {
"command": "npx",
"args": ["@zzaebok/mcp-wikidata@latest"]
}
}
Protegendo chaves de API:
{
"wikidata-mcp": {
"env": {
"WIKIDATA_API_KEY": "sua-chave-api"
}
}
}
Cursor
- Instale o Node.js e certifique-se de que o Cursor suporta MCP.
- Edite seu arquivo de configuração do Cursor.
- Adicione a entrada do Servidor MCP da Wikidata como mostrado.
- Salve as alterações e reinicie o Cursor.
- Verifique se o servidor está listado.
"mcpServers": {
"wikidata-mcp": {
"command": "npx",
"args": ["@zzaebok/mcp-wikidata@latest"]
}
}
Protegendo chaves de API:
{
"wikidata-mcp": {
"env": {
"WIKIDATA_API_KEY": "sua-chave-api"
}
}
}
Cline
- Certifique-se de que o Node.js está configurado.
- Atualize o arquivo de configuração do Cline com os detalhes do Servidor MCP.
- Adicione a configuração como abaixo.
- Salve e reinicie o Cline.
- Verifique a integração do servidor MCP.
"mcpServers": {
"wikidata-mcp": {
"command": "npx",
"args": ["@zzaebok/mcp-wikidata@latest"]
}
}
Protegendo chaves de API:
{
"wikidata-mcp": {
"env": {
"WIKIDATA_API_KEY": "sua-chave-api"
}
}
}
Como usar este MCP em fluxos
Usando MCP no FlowHunt
Para integrar servidores MCP ao seu fluxo de trabalho FlowHunt, comece adicionando o componente MCP ao seu fluxo e conectando-o ao seu agente de IA:
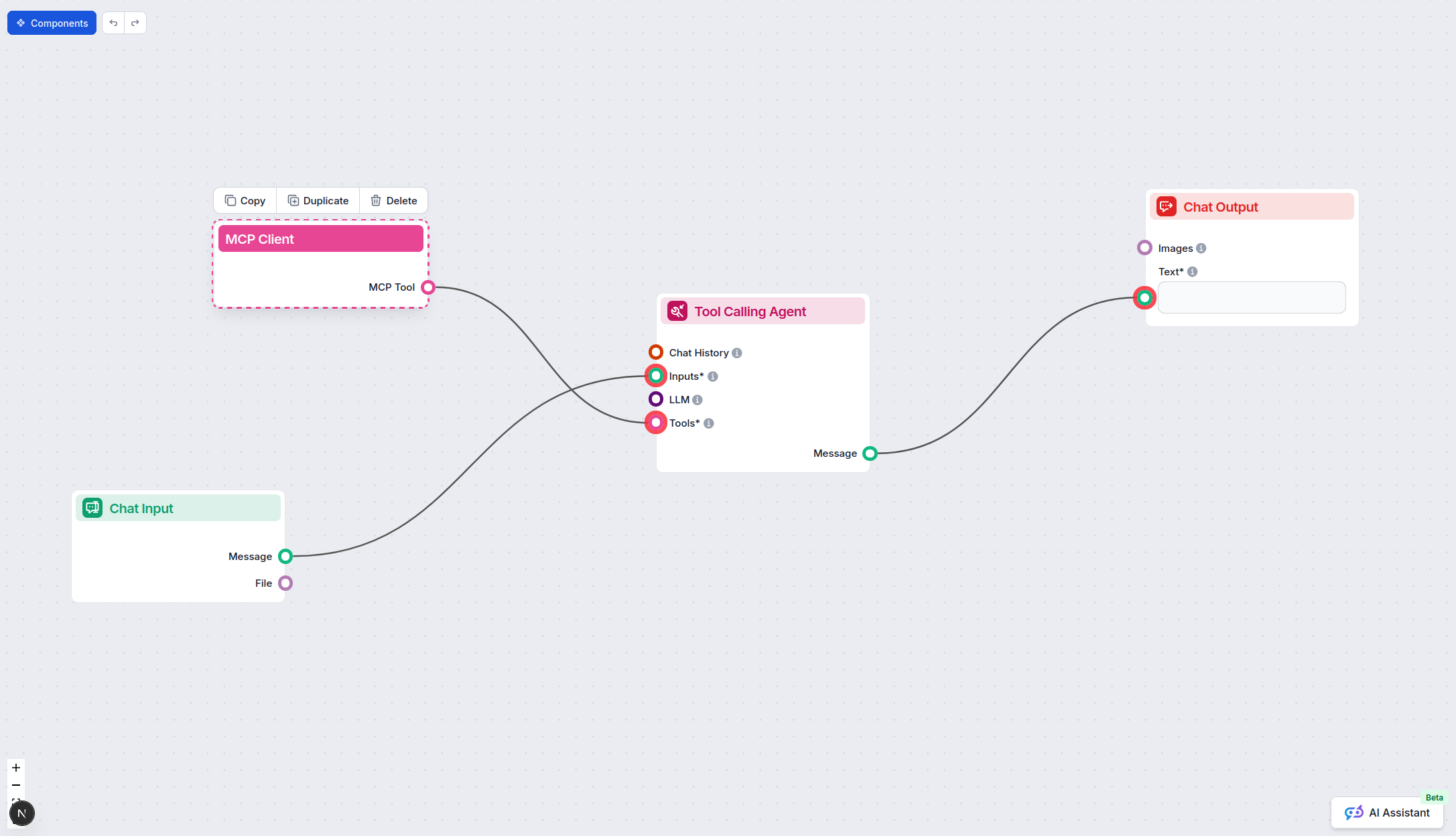
Clique no componente MCP para abrir o painel de configuração. Na seção de configuração MCP do sistema, insira os detalhes do seu servidor MCP usando este formato JSON:
{
"wikidata-mcp": {
"transport": "streamable_http",
"url": "https://seumcpserver.exemplo/caminhoparamcp/url"
}
}
Uma vez configurado, o agente de IA poderá utilizar este MCP como ferramenta com acesso a todas as suas funções e capacidades. Lembre-se de trocar “wikidata-mcp” pelo nome real do seu servidor MCP e substituir a URL pela URL do seu próprio servidor MCP.
Visão Geral
| Seção | Disponibilidade | Detalhes/Notas |
|---|---|---|
| Visão Geral | ✅ | Visão geral disponível em README.md |
| Lista de Prompts | ⛔ | Nenhum template de prompt encontrado |
| Lista de Recursos | ⛔ | Nenhum recurso explícito listado |
| Lista de Ferramentas | ✅ | Ferramentas detalhadas no README.md |
| Proteção de Chaves de API | ⛔ | Nenhuma exigência explícita de chave de API |
| Suporte a Amostragem (menos importante) | ⛔ | Não mencionado |
Nossa opinião
O Servidor MCP da Wikidata é uma implementação simples, mas eficaz, oferecendo diversas ferramentas úteis para interação com a Wikidata via MCP. No entanto, carece de documentação sobre templates de prompt, recursos e suporte a amostragem/roots, o que limita sua flexibilidade para integrações MCP mais avançadas ou padronizadas. A presença de licença, ferramentas claras e atualizações ativas fazem dele um ponto de partida sólido para casos de uso MCP focados na Wikidata.
Pontuação MCP
| Possui uma LICENÇA | ✅ (MIT) |
|---|---|
| Possui ao menos uma ferramenta | ✅ |
| Número de Forks | 5 |
| Número de Stars | 18 |
Avaliação do Servidor MCP: 6/10
Funcionalidade central sólida, mas falta suporte a recursos/prompt MCP padrão e funcionalidades avançadas. Bom para casos de uso de integração direta com a Wikidata.
Perguntas frequentes
- O que é o Servidor MCP da Wikidata?
O Servidor MCP da Wikidata é uma implementação do Model Context Protocol que conecta agentes e ferramentas de IA diretamente à API da Wikidata. Ele permite buscar entidades e propriedades, extrair metadados e executar consultas SPARQL para recuperação e enriquecimento avançados de dados semânticos.
- Quais ferramentas o Servidor MCP da Wikidata oferece?
Você pode buscar IDs de entidades e propriedades, obter propriedades de entidades, extrair rótulos e descrições e executar consultas SPARQL—tudo por meio de interfaces de ferramentas MCP simples.
- Como posso usar o Servidor MCP da Wikidata no FlowHunt?
Adicione o componente MCP ao seu fluxo, configure-o com os detalhes do seu Servidor MCP da Wikidata e conecte-o ao seu agente de IA. Isso permite que o agente utilize todas as ferramentas MCP da Wikidata em seus fluxos de trabalho.
- É necessário uma chave de API para usar o Servidor MCP da Wikidata?
Na maioria das configurações comuns, não é necessária uma chave de API para acessar dados públicos da Wikidata. Se sua implantação exigir uma chave de API (por exemplo, para proxies ou uso avançado), você pode especificá-la na configuração de ambiente do servidor.
- Quais são alguns casos de uso práticos?
Você pode utilizá-lo para recuperação de dados semânticos, enriquecimento de metadados, execução automatizada de consultas SPARQL, exploração de grafos de conhecimento e construção de recomendações baseadas em IA usando os dados estruturados da Wikidata.
Integre a Wikidata com o FlowHunt
Aprimore o raciocínio e as capacidades de dados da sua IA adicionando a Wikidata como fonte de conhecimento estruturado nos seus fluxos de trabalho do FlowHunt.
Saiba mais

