SpaCy
spaCy je rýchla a efektívna NLP knižnica v Pythone, ideálna pre produkciu s funkciami ako tokenizácia, POS tagging a rozpoznávanie entít.
spaCy je robustná open-source knižnica určená pre pokročilé spracovanie prirodzeného jazyka (NLP) v Pythone. Vydaná v roku 2015 Matthewom Honnibalom a Ines Montani, je udržiavaná spoločnosťou Explosion AI. spaCy je oceňované pre svoju efektívnosť, jednoduchosť použitia a komplexnú podporu NLP, vďaka čomu je preferovanou voľbou pre produkciu pred výskumnými knižnicami ako NLTK. Implementácia v Pythone a Cythone zabezpečuje rýchle a efektívne spracovanie textu.
História a porovnanie s inými NLP knižnicami
spaCy vzniklo ako silná alternatíva k iným NLP knižniciam vďaka zameraniu na priemyselnú rýchlosť a presnosť. Zatiaľ čo NLTK ponúka flexibilný algoritmický prístup vhodný pre výskum a vzdelávanie, spaCy je navrhnuté pre rýchle nasadenie v produkčných prostrediach s predtrénovanými modelmi pre bezproblémovú integráciu. spaCy poskytuje používateľsky prívetivé API, ideálne na efektívne spracovanie veľkých dátových súborov, a preto sa hodí pre komerčné aplikácie. Pri porovnaní s inými knižnicami, ako sú Spark NLP a Stanford CoreNLP, sa často vyzdvihuje rýchlosť a jednoduchosť spaCy, čo z neho robí optimálnu voľbu pre vývojárov požadujúcich robustné, produkčne pripravené riešenia.
Kľúčové vlastnosti spaCy
Tokenizácia
Rozdeľuje text na slová, interpunkčné znamienka a pod., pričom zachováva pôvodnú štruktúru textu – zásadné pre NLP úlohy.Označovanie častí reči (POS tagging)
Priraďuje slovné druhy tokenom ako podstatné mená a slovesá, poskytuje prehľad o gramatickej štruktúre textu.Analýza závislostí
Analyzuje štruktúru viet na určenie vzťahov medzi slovami a identifikuje syntaktické funkcie ako podmet či predmet.Rozpoznávanie pomenovaných entít (NER)
Identifikuje a kategorizuje pomenované entity v texte, ako sú osoby, organizácie a miesta, čo je zásadné pre extrakciu informácií.Klasifikácia textu
Kategorizuje dokumenty alebo ich časti, čo pomáha v organizácii a vyhľadávaní informácií.Podobnosť
Meria podobnosť medzi slovami, vetami alebo dokumentmi pomocou slovných vektorov.Pravidlové vyhľadávanie
Vyhľadáva sekvencie tokenov podľa ich textu a jazykových anotácií, podobne ako regulárne výrazy.Multitaskové učenie s transformermi
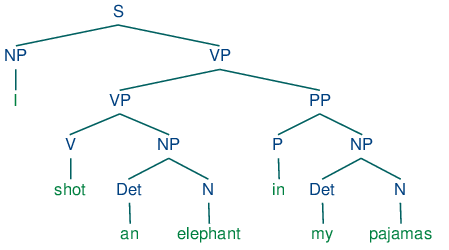
Integruje modely založené na transformer architektúre ako BERT, čím zvyšuje presnosť a výkon pri NLP úlohách.Vizualizačné nástroje
Obsahuje displaCy, nástroj na vizualizáciu syntaktickej štruktúry a pomenovaných entít, čo zlepšuje interpretáciu NLP analýz.Prispôsobiteľné pipeline
Umožňujú používateľom upraviť NLP workflow pridávaním alebo modifikovaním komponentov v spracovateľskej pipeline.
Príklady použitia
Dátová veda a strojové učenie
spaCy je neoceniteľné v dátovej vede pre predspracovanie textu, extrakciu príznakov a trénovanie modelov. Jeho integrácia s frameworkmi ako TensorFlow a PyTorch je kľúčová pre vývoj a nasadenie NLP modelov. Napríklad, spaCy dokáže predspracovať textové dáta tokenizáciou, normalizáciou a extrakciou príznakov ako pomenované entity, ktoré je možné ďalej využiť na analýzu sentimentu alebo klasifikáciu textu.
Chatboty a AI asistenti
Prirodzené porozumenie jazyku v spaCy je ideálne na vývoj chatbotov a AI asistentov. Zvláda úlohy ako rozpoznávanie zámeru a extrakciu entít, čo je zásadné pri tvorbe konverzačných AI systémov. Napríklad chatbot využívajúci spaCy vie porozumieť používateľským otázkam identifikovaním zámerov a vyhľadávaním relevantných entít, čo mu umožní generovať vhodné odpovede.
Extrakcia informácií a analýza textu
SpaCy sa široko používa na extrakciu štruktúrovaných informácií z neštruktúrovaného textu, dokáže kategorizovať entity, vzťahy a udalosti. To je užitočné v aplikáciách ako analýza dokumentov a extrakcia znalostí. Napríklad pri analýze právnych dokumentov spaCy vyextrahuje kľúčové informácie, ako sú zúčastnené strany a právne pojmy, čím automatizuje kontrolu dokumentov a zvyšuje efektivitu pracovného postupu.
Výskum a akademické aplikácie
Vďaka komplexným NLP možnostiam je spaCy cenným nástrojom pre výskum a akademické účely. Výskumníci môžu skúmať jazykové vzorce, analyzovať textové korpusy a vyvíjať doménovo špecifické NLP modely. Napríklad spaCy možno použiť v lingvistickej štúdii na identifikáciu vzorcov jazykového používania v rozličných kontextoch.
Príklady použitia spaCy v praxi
Rozpoznávanie pomenovaných entít
import spacy nlp = spacy.load("en_core_web_sm") doc = nlp("Apple is looking at buying U.K. startup for $1 billion") for ent in doc.ents: print(ent.text, ent.label_) # Output: Apple ORG, U.K. GPE, $1 billion MONEYAnalýza závislostí
for token in doc: print(token.text, token.dep_, token.head.text) # Output: Apple nsubj looking, is aux looking, looking ROOT looking, ...Klasifikácia textu
spaCy je možné rozšíriť vlastnými modelmi na klasifikáciu textu podľa vopred definovaných kategórií.
Balenie a nasadzovanie modelov
spaCy poskytuje robustné nástroje na balenie a nasadenie NLP modelov, čím zabezpečuje produkčnú pripravenosť a jednoduchú integráciu do existujúcich systémov. To zahŕňa podporu verzovania modelov, správu závislostí a automatizáciu workflow.
Výskum o SpaCy a súvisiacich témach
SpaCy je široko využívaná open-source knižnica v Pythone pre pokročilé spracovanie prirodzeného jazyka (NLP). Je určená pre produkčné použitie a podporuje rôzne NLP úlohy ako tokenizácia, označovanie častí reči a rozpoznávanie pomenovaných entít. Nedávne vedecké práce zdôrazňujú jej aplikácie, vylepšenia a porovnania s inými NLP nástrojmi, čím rozširujú naše poznatky o jej možnostiach a nasadeniach.
Vybrané vedecké práce
| Názov | Autori | Dátum publikácie | Zhrnutie | Odkaz |
|---|---|---|---|---|
| Multi hash embeddings in spaCy | Lester James Miranda, Ákos Kádár, Adriane Boyd, Sofie Van Landeghem, Anders Søgaard, Matthew Honnibal | 2022-12-19 | Diskutuje implementáciu multi hash embeddings v spaCy na zníženie pamäťovej náročnosti slovných embeddingov. Hodnotí tento prístup na NER datasetoch, potvrdzuje dizajnové rozhodnutia a odhaľuje neočakávané zistenia. | Viac tu |
| Resume Evaluation through Latent Dirichlet Allocation and Natural Language Processing for Effective Candidate Selection | Vidhita Jagwani, Smit Meghani, Krishna Pai, Sudhir Dhage | 2023-07-28 | Predstavuje metódu hodnotenia životopisov pomocou LDA a rozpoznávania entít v spaCy, dosahuje 82% presnosť a podrobne opisuje výkon NER v spaCy. | Viac tu |
| LatinCy: Synthetic Trained Pipelines for Latin NLP | Patrick J. Burns | 2023-05-07 | Predstavuje LatinCy, NLP pipeline kompatibilné so spaCy pre latinu, ukazuje vysokú presnosť v POS tagovaní a lematizácii, demonštruje prispôsobivosť spaCy. | Viac tu |
| Launching into clinical space with medspaCy: a new clinical text processing toolkit in Python | Hannah Eyre, Alec B Chapman, et al. | 2021-06-14 | Predstavuje medspaCy, klinickú textovú sadu nástrojov postavenú na spaCy, spájajúcu pravidlové a ML prístupy pre klinické NLP. | Viac tu |
Najčastejšie kladené otázky
- Čo je spaCy?
spaCy je open-source knižnica v Pythone pre pokročilé spracovanie prirodzeného jazyka (NLP), navrhnutá pre rýchlosť, efektívnosť a produkčné nasadenie. Podporuje úlohy ako tokenizácia, označovanie častí reči, analýza závislostí a rozpoznávanie pomenovaných entít.
- Ako sa spaCy líši od NLTK?
spaCy je optimalizované pre produkčné prostredie s predtrénovanými modelmi a rýchlym, používateľsky prívetivým API, vďaka čomu je ideálne na spracovanie veľkých dátových súborov a komerčné využitie. NLTK je naopak viac zamerané na výskum a ponúka flexibilné algoritmické prístupy vhodné na vzdelávanie a experimentovanie.
- Aké sú hlavné vlastnosti spaCy?
Kľúčové vlastnosti zahŕňajú tokenizáciu, POS tagging, analýzu závislostí, rozpoznávanie pomenovaných entít, klasifikáciu textu, meranie podobnosti, pravidlové vyhľadávanie, integráciu transformerov, vizualizačné nástroje a prispôsobiteľné NLP pipeline.
- Aké sú bežné použitia spaCy?
spaCy je široko používané v dátovej vede na predspracovanie textu a extrakciu príznakov, pri tvorbe chatbotov a AI asistentov, na extrakciu informácií z dokumentov a vo vedeckom výskume na analýzu jazykových vzorcov.
- Dá sa spaCy integrovať s frameworkmi hlbokého učenia?
Áno, spaCy je možné integrovať s frameworkmi ako TensorFlow a PyTorch, čo umožňuje bezproblémový vývoj a nasadenie pokročilých NLP modelov.
- Je spaCy vhodné pre špecializované domény ako zdravotníctvo alebo právo?
Áno, flexibilné API a rozšíriteľnosť spaCy umožňujú jeho prispôsobenie pre špecializované oblasti, napríklad spracovanie klinických textov (napr. medspaCy) a analýzu právnych dokumentov.
Objavujte AI so spaCy
Zistite, ako môže spaCy poháňať vaše NLP projekty – od chatbotov až po extrakciu informácií a výskumné aplikácie.
Zistiť viac