
Vyhľadávač dokumentov
Vyhľadávač dokumentov od FlowHunt zvyšuje presnosť AI tým, že prepája generatívne modely s vašimi aktuálnymi dokumentmi a URL adresami, čím zabezpečuje spoľahli...
4 min čítania
AI
Document Retrieval
+3
Naučte sa, ako nastaviť parametre ‘From H1 if exists’, ‘Load from pointer’ a ‘Skip Last Header’.
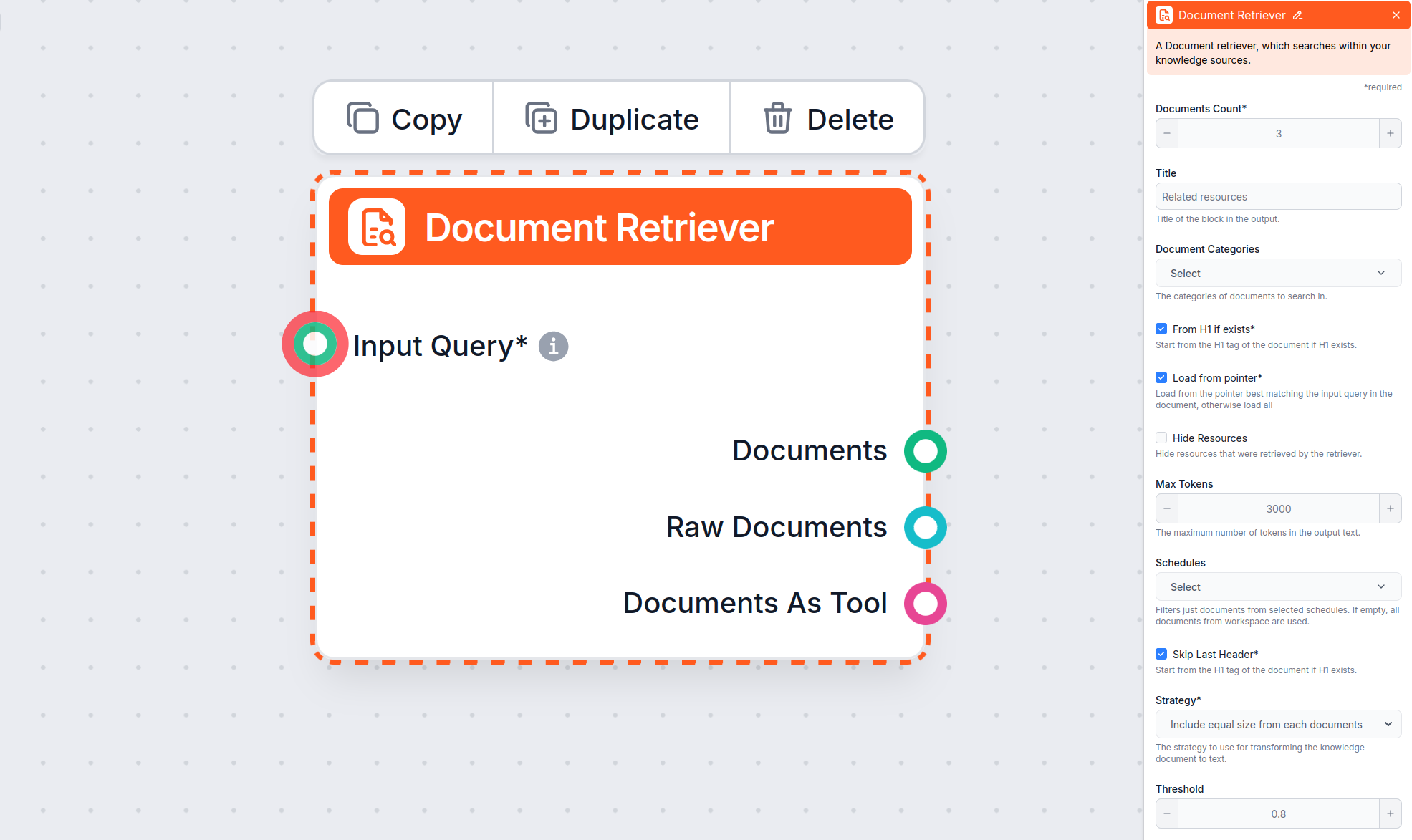
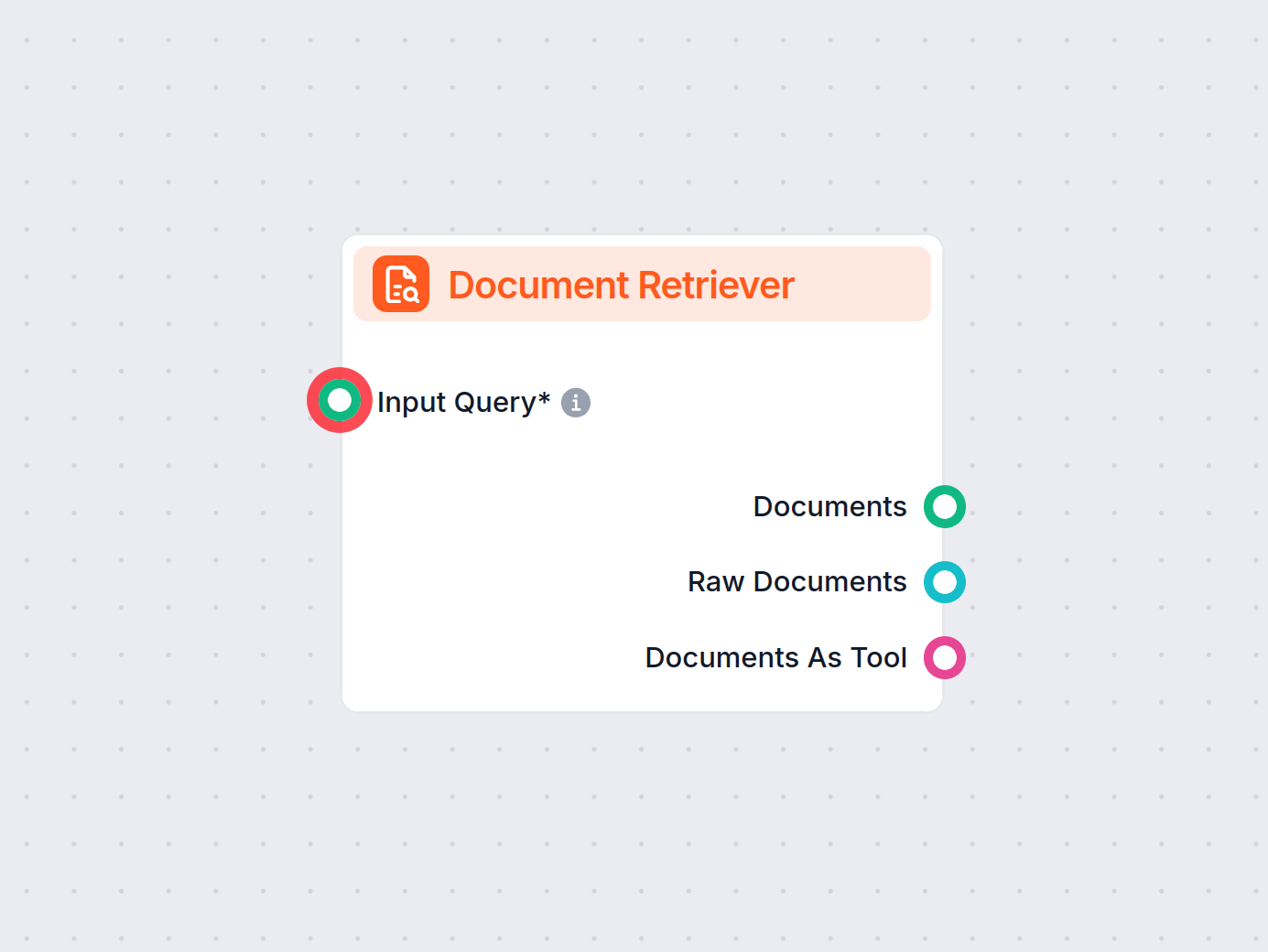
Komponent Document Retriever umožňuje chatbotovi získavať znalosti zo zdrojov, ktoré ste zadali v sekciách Dokumenty a Plány. Úlohou tohto komponentu je riadiť vyhľadávanie informácií a viaceré parametre ovplyvňujú, ako komponent informácie z týchto dokumentov získava.
Voľba From H1 if exists nastavuje retriever tak, aby začal extrahovať obsah od H1 nadpisu, ktorý nájde (zvyčajne hlavný titulok článku).
Čo sa stane?
Príklad použitia:
Chcete načítať iba samotný návod, bez zbytočnej navigácie alebo hlavičky stránky, ktorá sa nachádza na vašom webe.
Poznámka:
From H1 if exists je v komponente Document Retriever predvolene zapnuté.
Možnosť Load from pointer vám poskytuje väčšiu presnosť, pretože Document Retriever načíta len údaje od zadaného ukazovateľa v prípadne dlhšieho článku.
Čo sa stane?
Čo je “pointer”?
Pointer je zvyčajne unikátny reťazec alebo nadpis v dokumente (napríklad H2 alebo konkrétna fráza či názov sekcie).
Príklad použitia:
Chcete preskočiť úvodné sekcie a získať informácie pre konkrétnu relevantnú časť prípadne dlhého článku alebo dokumentu (napr. od “Krok 4: Pridajte tlačidlo live chatu” v návode na nastavenie).
Možnosť Skip Last Header je užitočná, ak chcete ignorovať posledný nadpis v dokumente, ktorý býva často opakovaný alebo slúži na navigáciu či ako pätička.
Čo sa stane?
Príklad použitia:
Chcete, aby Document Retriever nenačítal navigačný nadpis pätičky (napríklad “Ďalšie články” na konci stránky helpdesku), čím zabezpečíte, že sa spracuje len hlavný obsah.
Poznámka:
Skip Last Header môže pomôcť pri dokumentoch, ktoré automaticky generujú pätičky alebo opakujúce sa navigačné prvky. Ak však takéto sekcie nemáte, použitie tohto parametra môže spôsobiť, že časť článku s platnými informáciami nebude načítaná. Preto odporúčame túto možnosť ponechať vypnutú, pokiaľ nemáte konkrétny dôvod ju aktivovať.
Parameter Max tokens vám umožňuje nastaviť maximálny počet tokenov (slov a interpunkčných znamienok, ako ich počíta AI model), ktoré Document Retriever vyextrahuje z textu.
Čo sa stane?
Predvolená hodnota:
Predvolená hodnota je zvyčajne 3000 tokenov, no podľa potreby ju môžete upraviť.
Príklad použitia:
Ak spracovávate rozsiahle dokumenty, nižšia hodnota Max tokens pomáha udržať odpovede stručné. Pre najlepšie výsledky však zvážte aj aktiváciu parametra “Load from pointer”. Tak zaistíte, že extrahovaný text začne v najrelevantnejšej časti dokumentu, nie od začiatku, a získate sústredený a zvládnuteľný blok informácií v rámci zadaného limitu tokenov. Táto kombinácia je zvlášť užitočná, ak chcete krátke a kontextuálne relevantné výstupy z veľkých zdrojov.
Poznámka:
Ak zistíte, že informácie sú orezané, skúste zvýšiť hodnotu Max tokens. Ak chcete kratšie a sústredenejšie výstupy, znížte parameter Max tokens.
Ak Document Retriever nájde niekoľko relevantných dokumentov, parameter Strategy určuje, ako sa spoja do jedného textového výstupu pre váš chatbot, pričom berie do úvahy aj limit “Max tokens”.
Dve možnosti stratégie:
Include equal size from each document:
Limit tokenov sa rozdelí rovnomerne. Napríklad, ak máte tri dokumenty a limit 3000 tokenov, každý dostane až 1000 tokenov. Všetky zdroje tak prispievajú rovnako, čo je užitočné, ak chcete vyváženú odpoveď čerpajúcu z viacerých dokumentov.
Concat documents, fill from first up to the tokens limit:
Dokumenty sa pridávajú podľa relevantnosti, kým sa nenaplní limit tokenov. Najrelevantnejší dokument zaplní priestor ako prvý; ak zostane miesto, doplnia sa menej relevantné dokumenty podľa poradia. Ak je prvý dokument dlhý, môže vyčerpať celý limit sám.
Ako si vybrať?
Poznámka:
Tieto stratégie ovplyvňujú len to, ako je text zostavený z vyextrahovaných dokumentov predtým, než prejde do ďalšieho kroku (napríklad AI generovania). Nemenia, ktoré dokumenty sa získajú – iba to, ako sa ich obsah spojí a oreže tak, aby sa zmestil do nastaveného limitu Max tokens.
Hoci sa tento článok zameriava na nastavenie parametrov ‘From H1 if exists’, ‘Load from pointer’, ‘Skip Last Header’ a ‘Max tokens’, Document Retriever ponúka aj ďalšie parametre, ktoré pomáhajú určovať, ako sa dokumenty vyberajú a načítavajú:
Toto nastavenie limituje počet dokumentov, ktoré má flow načítať, čím zabezpečuje relevantnosť výsledkov a rýchlu odozvu.
Toto voliteľné nastavenie umožňuje obmedziť načítavanie iba na jednu alebo viac kategórií, ktoré ste vytvorili v sekcii Dokumenty v Zdrojoch znalostí.
Umožňuje zahrnúť alebo skryť samostatnú sekciu pred samotnou odpoveďou chatbota s výpisom zdrojov, ktoré retriever načítal. Pre integráciu s LiveAgent musí byť táto možnosť zaškrtnutá, pretože táto sekcia nie je podporovaná a v LiveAgent chatbote by sa nezobrazila správne.
Umožňuje obmedziť načítavanie na jeden alebo viac plánov, ktoré ste zadali pre prehľadávanie alebo aktualizáciu obsahu v Zdrojoch znalostí.
Určuje, ako presne sa musia dokumenty zhodovať so zadaným dopytom, pomocou skóre relevantnosti (od 0 do 1). Napríklad pre veľmi relevantné odpovede sa odporúča threshold 0,7–0,8. Vyššie prahy dajú presnejšie zhodné dokumenty, nižšie môžu zahrnúť aj menej relevantné.
Príklad:
Ak nastavíte threshold na 0,6 a máte štyri články s relevanciou 0,8, 0,65, 0,5 a 0,9, použijú sa len tie nad 0,6 (teda 0,8, 0,65 a 0,9) na extrakciu.
Ak odpoveď od chatbota neobsahuje informáciu, o ktorej ste presvedčení, že ju má vo vašich dokumentoch alebo plánoch k dispozícii, skúste skontrolovať históriu konverzácie s voľbou “Verbose”, aby ste videli detailné logy o tom, či bol Document Retriever použitý a aké dokumenty načítal. V prípade potreby podľa týchto logov upravte svoje nastavenia a prompt.
Vyhľadávač dokumentov od FlowHunt zvyšuje presnosť AI tým, že prepája generatívne modely s vašimi aktuálnymi dokumentmi a URL adresami, čím zabezpečuje spoľahli...
Váš chatbot môže okamžite pristupovať a využívať dokumenty, HTML stránky a dokonca aj YouTube videá na prispôsobenie vášho jedinečného kontextu. Ideálne na prid...
Integrujte svoje pracovné postupy s Google Docs pomocou komponentu Google Docs Retriever—jednoducho načítajte obsah dokumentov na použitie v automatizáciách, ch...